Rust 基础语法与核心概念
Rust基础
如果使用的是 RustRover 作为开发 IDE 的话,需要到运行中关闭运行前编译,否则开发过程中运行会变的很慢
一、Cargo
bash# 创建一个新项目
cargo new hello_cargo
# 在已有项目使用cargo
cargo init初始化项目后会生成标准的包结构
toml# ./Cargo.toml
[package]
name = "项目名称",
version = "项目版本"
authors = "项目作者"
edition = "使用的Rust版本"
[dependencies]
# 项目依赖,在Rust中包称之为crate rust// ./src/main.rs
fn main(){
println!("hello word")
}构建Cargo项目
cargo build构建开发版本:target/dubug/hello_cargo(.exe)
cargo run创建并执行文件
cargo check检查代码,确保可以编译通过,不产生文件,提高效率
cargo build --release构建发布版本:target/release/hello_cargo(.exe)
二、猜数字游戏
toml[package]
name = "demo"
version = "0.1.0"
edition = "2021"
[dependencies]
rand = "^0.8.5" rust// main.rs
use std::io;
use std::cmp::Ordering;
use rand::Rng;
fn main() {
// 类型可以为 i32 u32 i64
let secret_number = rand::thread_rng().gen_range(1..101);
println!("猜数字游戏!!");
loop {
eprint!("请输入数字:");
let mut input = String::new();
io::stdin().read_line(&mut input).expect("读取失败");
// trim 去除字符串的前后空格 parse 将字符串转换为i32
let input: i32 = input.trim().parse().expect("输入错误");
match input.cmp(&secret_number) {
Ordering::Less => println!("猜小了"),
Ordering::Greater => println!("猜大了"),
Ordering::Equal => {
println!("猜对了");
break;
}
}
}
}三、变量与可变性
声明变量使用
let关键字默认情况,变量是不可变的 (lmmutable)
rustfn main() {
// 不可变
let a = 1;
// 可变
let mut b = 12;
}变量和常量
- 常量(constant),窗帘在绑定值以后也是不可变的,但是他与不可变的变量有区别
- 常量不可以使用mut关键字,常量永远不可变
- 声明常量必须使用const关键字,他的类型必须被标注
- 窗帘可以在任何作用域声明,包括全局作用域
- 常量只可以绑定到常量表达式,无法绑定到函数的调用结果或者只能在运行时计算出的值
- 在程序运行期间,常量在其声明的作用域内一直有效
- 命名规则:Rust里常量使用全大写字母,每个单词质检用下划线分开,例如:
const MAX_WIDTH: u32 = 128_000;
Shadowing(变量遮蔽)
可以使用相同名字声明新的变量,新的变量就会shadow(隐藏)之前声明的同名变量
在后续的代码中这个变量名代表的就是新的变量
- rust
fn main() { let a = 1; let a = a * 2; }
shadow和把变量标记为mut是不一样的
如果不是使用let关键字,那么重新给非mut的变量赋值会导致编译错误
而使用let声明的同名新变量,也是不可变的
使用了let声明的同名新变量,他的类型可以与之前不同
- rust
fn main() { let spaces = " "; let spaces = spaces.len(); println!("{}", spaces) }```
四、数据类型
- 标量和符合类型
- Rust是静态编译语言,在编译时必须知道所有变量的类型
- 基于使用的值,编译器通常能够推断出他的具体类型
- 但如果可能的类型比较多(例如String转为整数的parse方法),就必须添加类型的标注,否者编译就会报错
标量类型
- 一个标量类型代表一个单个的值
整数类型
- 整数类型没有小数部分
- 例如 u32就是一个无符号的整数类型,占据32位的空间
- 无符号整数类型以u开头
- 有符号类型以i开头
- 有符号范围:[ -(2^n -1) 到 2^(n-1) -1 ]
- 无符号范围:[0 到 2^n -1]
| Length | Signed | Unsigned |
|---|---|---|
| 8bit | i8 | u8 |
| 16bit | i16 | u16 |
| 32bit | i32 | u32 |
| 64bit | i64 | u64 |
| 128bit | i128 | u128 |
| arch | isize | usize |
isize和usize类型的位数由程序运行的计算机的架构决定
如果是64位计算机,那么就是64位
整数字面值
| Number literals | Example |
|---|---|
| Decimal | 98_222 |
| Hex | 0xff |
| Octal | 0o77 |
| Binary | 0b1111_0000 |
| Byte(u8 only) | b'A' |
除了byte类型外所有的数值字面值都允许使用类型后缀
如:57u8
整数的默认类型就是i32
总体来说速度很快,即使在64位系统中
整数溢出
u8的范围是0-255,如果你把一个u8变量的值设位256,那么
调试模式下,Rust后检查整数溢出,如果发生溢出,程序在运行时就会panic
发布模式(--release)下Rust不会检查可能导致panic的整数溢出
溢出后会执行环绕操作
256-->0, 257-->1
浮点类型
Rust有两种基础的浮点类型,也就是含有小数部分的类型
f32, 32位单精度
f64, 64位双精度
Rust的浮点类型使用 IEEE-754 标准来描述
f64 是默认类型,因为现代CPU上 f64 和 f32 的熟读差不多,而且精度更高
rustlet a = 2.0;
let a: f32 = 3.0;数值操作
rustlet sum = 5 + 10;
let difference = 91.1 - 4.3;
let product = 4 * 20;
let quotient = 56.7 / 32.2
let reminder = 54 % 5布尔类型
Rust的布尔类型也有两个值 true 和 false
一个字节大小
符号是 bool
字符类型
Rust语言中char类型被用来描述语言中最基础的单个字符
字符类型的字面值使用单引号
占用4个字节大小
是Unicode标量值,可以表示比ASCII多得多的字符内容:拼音、中日韩文、零长度空白字符、emoji表情等
五、复合类型
可以将多个值放到一个类型中
元组(Tuple)
- Tuple可以将多个类型的多个值放到一个类型中
- 长度是固定的,一旦声明就无法修改
声明元组
rustlet tup: (i32, f32, u8) = (500, 3.4, 13);获取元组元素值
- 可以使用模式匹配来解构 (destructure) 一个元组来获取元素值
rustlet tup: (i32, f32, u8) = (500, 3.4, 13);
let (x, y, z) = tup;访问元组的元素
- 使用点标记法, 后接元素索引
rustprintln!("{}, {}, {}", tup.0, tup.1, tup.2);数组
数组也可以将多个值放到一个类型中
每个元素的类型必须相同
长度固定
声明数组
rustlet array = [1, 2, 3, 4, 5];
// 5 个 3
let arr2 = [3; 5]
// u8字节缓存数组,这里的 0u8 代表填充 1024 个类型为无符号8bit整数的0
let buffer = [0u8; 1024]数组的用处
- 让数据存放在stack(栈)上而不是heap(堆)上,多种想保证有固定数量的元素
- 数组没有Vector灵活
- 与数组类似,由标准库提供
数组的类型
数组的类以 [类型; 长度]来表示
rustlet array: [u8; 5] = [1, 2, 3, 4, 5];访问数组元素
- 数组是Stack上分配的单个块的内存
- 可以使用索引来访问数组的元素
- 如果访问的索引超出了数组范围
- 编译会通过
- 运行时会报错(runtime 时会 panic)
- Rust不会允许其继续访问相应地址的内存
rustlet value = array[0]六、函数
- 声明函数使用
fn关键字 - 针对函数和变量名,Rust使用snake case命名规范
- 所有的字母都是小写,单词之间使用下划线分开
rustfn main() {
printlbn!("hello world");
another_function();
}
fn another_function() {
println!("Another function");
}函数的参数
- parameters,arguments
- 函数签名里必须声明类型
rustfn add(a: i32, b: i32) {
return a + b;
}函数体中的语句与表达式
- 函数体由一系列语句组成,可选的由一个表达式结束
- Rust是一个基于表达式的语言
- 语句是执行一些动作的指令
- 表达式会产生一个值
rustfn main() {
let x = 5;
let y = {
let x = 1;
// 没有分号会吧这个值返回
x + 20
};
println!("{} --> {}", x, y)
}函数的返回值
- 在
->符号后面声明函数返回值类型,但是不可以为返回值命名 - 在Rust里面,返回值就是函数体里面最后一个表达式的值
- 大多数函数都是迷哦人使用最后一个表达式做为返回值
rustfn main() {
let x = five()
println!("{}", x)
}
fn five() -> i32 {
5
}七、注释
rust// 单行
/*
多行
*/八、循环
rustfn main() {
let mut flag = 1;
loop {
flag += 1;
if flag > 5 {
break;
};
};
while flag == 6 {
println!("{flag} == 6");
break;
};
let x = [3; 5];
for item in x.iter() {
println!("{item}");
};
println!("{:?}", x);
}Range
生成一个开始数字和结束数字,range可以生成他们之间的数(前取后不取)
rev方法可以反转Range
rustfn main() {
// 正向range [0-99]
for i in 0..100 {
println!("... {i}");
};
// 反向 [19-1]
for i in (0..20).rev() {
println!("<... {i}")
}
println!("{:?}", x);
}
九、所有权
所有权是Rust最独特的特性,他让Rust无需GC就可以保证内存安全
Rust的核心特性就是所有权
所有程序在允许时都必须挂历他们使用计算机内存的方式
有些语言有垃圾回收机制,在程序运行时,他们会不断的寻找不再使用的内存
在其他一些语言中,必须显式的分配和释放内存
Rust采用了第三种方式:
内存是同个一个所有权系统来管理,其中包含一组编译器在编译时检查的规则
当程序运行时,所有权特性不会减慢程序的运行速度
Stack(栈内存) vs Heap(堆内存)
- 在像Rust这样的系统级编程语言里,一个值是在stack还是在heap上对语言的行为和你为什么要做某些觉得是有更大的影响的
- 在代码运行的时候,stack和heap都是可用的你内存,但他们的结构很不相同
存储方式
- Stack按值的接收顺序来存储,按相反的顺序将他们移除(后进先出,LIFO)
- 添加数据叫压入栈
- 移除数据叫弹出栈
- 所有存储在Stack上的数据必须拥有已知的固定的大小
- 编译时大小未知的数据或运行时的大小可能发生变换的数据必须存放在heap上
- Heap内存组织性差一些
- 当你把数据放入heap时,你会请求一定数量的空间
- 操作系统在heap里找到一块足够大的空间,把他标记为在用,并返回一个指针,也就是这个空间的内存地址
- 这个过程叫做在heap上进行分配,有时仅仅称为“分配”
存储数据
- 把值压到stack上不叫分配
- 因为指针是已知固定大小的,可以把指针存放在stack上
- 但如果想要实际数据,你必须使用指针来定位
- 把数据压到stack上要比在heap上分配快得多
- 因为操作系统不需要寻找用来存储新数据的空间,那个位置永远在stack的顶端
- 在heap上分配空间需要做更多的工作
- 操作系统首先需要一个足够大的空间来存放数据,然后记录方便下次分配
访问数据
- 访问heap中的数据要比访问stack中的数据慢,因为需要通过指针才能找到heap中的数据
- 对于现代的处理器来说,由于缓存的缘故,如果指令在内存中跳转的次数越少,那么熟读就越快
- 如果数据存放的距离比较近,那么处理器的处理熟读就会更快一些(stack上)
- 如果数据之间的距离比较远,那么处理速度就会慢一些(heap上)
- 在heap上分配大量空间也是耗时的
函数调用
- 当代码调用函数时,值被传入到函数(也包括指向heap的指针)。函数本地的变量被压到stack上。当函数结束后,这些值会从stack上弹出
所有权存在的原因
- 所有权解决的问题
- 跟踪代码的哪部分正在使用heap的哪些数据
- 最小化heap上的重复数据量
- 清理heap上未使用的数据以避免空间不足
- 使用了所有权,就不需要经常去想stack或heap了
所有权规则
- 每个值都有一个变量,这个变量是该值的所有者
- 每个值同时只能有一个所有者
- 当所有者超出作用域(scope)时,该值将被删除
变量作用域
- Scope就是重新中一个项目的有效范围
rustfn main() {
// s不可用
let s = "hello" // s声明
// 可以对s操作
} // s作用域结束,不再可用String类型
- String比标量类型更复杂
- 字符串字面值:重新里手写的哪些字符串值,他们是不可变的
- Rust的第二种字符串类型:String
- 在heap上分配, 能够存储在编译时未值数量的文本
创建String类型的值
可以使用from函数从字符串字面值创建出String类型
rustlet s = String::from("hello");::表示from是String类型下的函数
这类字符串是可以被修改的
rustfn main() { let mut s = String::from("hello"); // s后添加字符串 s.push_str(", world!"); println!("{}", s); }String类型的值可以修改(可以在原有字符串后面做修改),而字符串字面值却不能修改(不可变类型重新创建)
- 因为他们处理内存的方式不同
内存和分配
- 字符串字面值,在编译时就知道它的内容,其文本内容直接被硬编码到最终的可执行文件里
- 由于不可变性所以速度快、高效
- String类型,为了支持可变性,需要在heap上分配内存来保存编译时未知的文本内容
- 操作系统必须在运行时来请求内存
- 这部通过调用
String::from来实现
- 这部通过调用
- 当用完String之后,需要使用某种方式将内存返回给操作系统
- 这步,在拥有GC的语言中,GC会跟踪并清理不再使用的内存
- 没有GC,就需要我们去识别内存合适不再使用,并调用代码将它返回
- 如果忘了,浪费内存
- 提前了,变量非法
- 必须做到一次分配对应一次释放
- 操作系统必须在运行时来请求内存
- Rust采用了不同的方式:对于某个值来说,当拥有它的变量走出作用域范围时,内存会立即自动的交还给操作系统
- drop函数,释放变量
变量和数据交互的方式:移动(Move)
多个变量可以与同一个数据使用一种独特的方式来交互
rustlet x = 5; let y = y;整数是已知且固定大小的简单值,这两个5被压到了stack中
String版本
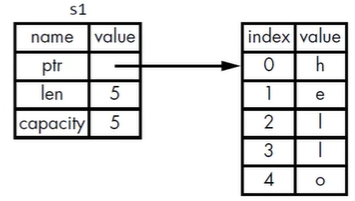
rustlet s1 = String::from("hello"); let s2 = s1;- 一个String由3部分组成:
- 一个指向存放内容的内存的指针
- 一个长度
- 一个容量
- S1的内容放到stack中
- ptr指向的是heap中的,字符串的内容在heap中
- 长度就是len,存放字符串内容所需要的字节数
- 容量就是capacity,代表String从操作系统中总共获得内存的字节总数
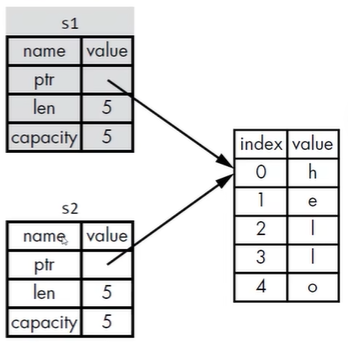
- 把S1赋值给了S2,String的数据被复制了一份
- 在stack上赋值了一份指针、长度、容量
- 并没有赋值heap上的数据
- 当变量离开作用域Rust会自动调用drop函数,帮将变量使用的heap内存释放
- 当S1、S2离开作用域是,他们都会尝试释放相同内存
- 二次释放(double free)bug
- 为了保证内存安全
- Rust没有尝试赋值被分配的内存
- Rust让S1失效
- 当si离开作用域时,Rust不需要释放任何东西
- 把S1赋值给别的变量后S1就会失效
- 一个String由3部分组成:
- 浅拷贝(shallow copy)
- 深拷贝(deep copy)
- 上面的复制S1内容可能被视未浅拷贝,但是他同时让S1变量失效了,所以这里叫 移动(Move)
Rust不会自动创建数据的深拷贝
- 就运行时性能而言,仍和赋值操作都是廉价的
如果真的需要对heap上面的String数据进行深拷贝,而不仅仅是stack上的数据,可以使用clone方法
rustfn main() { let mut s1 = String::from("hello"); let mut s2 = s1.clone(); println!("{} {}", s1, s2); }
Stack上的数据:复制
rustfn main() {
let mut s1 = 18;
let mut s2 = s1;
println!("{} {}", s1, s2);
}- Copy trait,可以用于像整数这样完全存放在stack上面的类型
- 如果一个类型实现了Copy这个trait,那么旧的变量在赋值后仍然可用
- 如果一个类型或者该类型的一部分实现了Drop trait,那么Rust不允许让他在去实现Copy trait
- 一些拥有Copy trait的类型
- 任何简单标量的组合类型都可以是Copy的
- 任何需要分配内存或某种资源的都不是Copy的
所有权与函数
在语义上,将值传递给函数和把值赋给变量是类似的
- 将值传递给函数要么会发生移动或赋值
rustfn main() { let s = String::from("hello"); func1(s); // 这时s已经被移动到func1中,不能再使用 let x = 5; func2(x); println!("{}", x) } fn func1(some_string: String) { println!("{}", some_string) } fn func2(x: i8) { println!("{}", x) }rustfn main() { let s1 = get_string(); let s2 = String::from("Hello World!"); let s3 = take_string(s2); // s2被所有权被移动此时s2无效 println!("{} {}", s1, s3) } fn get_string() -> String { let value = String::from("Hello World!"); return value; } fn take_string(s: String) -> String { return s; }一个变量的所有权总是遵循同样的模式
- 把一个值赋给其他变量是就会发生移动
- 当一个包含heap数据的变量离开作用域时,它的值就会被drop函数清理,除非数据的所有权移动到另一个变量上了
函数使用某个值,但不获得器所有权
Rust有一个特性叫做 引用(Reference)
- 参数的类型是
&String为不是 String &符号便是引用:允许你应用某些值而不取得其所有权- 本质上就是传入按函数是是变量stack上数据的指针,而stack上数据由指向了heap上的数据
rustfn main() { let mut s1 = String::from("Hello World!"); get_string(&mut s1); println!("{}", s1); println!("{}", get_len(s1)); } fn get_string(s: &mut String) { s.push_str("你好世界!"); } fn get_len(s: &String) -> i32 { retrun s.len() }- 参数的类型是
借用
我们把引用作为函数参数这个行为叫借用
和变量一样默认引用是不可变的
&mut String可变引用
可变引用在一个特定的作用域内,对某一块数据,只能有一个可变引用
- 在编译时防止数据竞争
以下三种行为会发生数据竞争
- 两个及以上指针同时访问同一个数据
- 只是有一个指针用于写入数据
- 没有使用任何机制来同步对数据的访问
通过创建新的作用域,来允许非同时的创建多个可变引用
rustfn main() { let mut s1 = String::from("Hello World!"); { let s2 = &mut s1; } let s3 = &mut s1; }不可以捅死拥有一个可变引用和一个不可变引用
多个可变引用是可以的(不可变引用要在可变引用后restc E0502)
ref模式rust#[derive(Clone, Copy)] struct Point { x: i32, y: i32 } fn main() { let c = 'Q'; // 赋值语句中左边的 `ref` 关键字等价于右边的 `&` 符号。 let ref ref_c1 = c; let ref_c2 = &c; println!("ref_c1 equals ref_c2: {}", *ref_c1 == *ref_c2); let point = Point { x: 0, y: 0 }; // 在解构一个结构体时 `ref` 同样有效。 let _copy_of_x = { // `ref_to_x` 是一个指向 `point` 的 `x` 字段的引用。 let Point { x: ref ref_to_x, y: _ } = point; // 返回一个 `point` 的 `x` 字段的拷贝。 *ref_to_x }; // `point` 的可变拷贝 let mut mutable_point = point; { // `ref` 可以与 `mut` 结合以创建可变引用。 let Point { x: _, y: ref mut mut_ref_to_y } = mutable_point; // 通过可变引用来改变 `mutable_point` 的字段 `y`。 *mut_ref_to_y = 1; } println!("point is ({}, {})", point.x, point.y); println!("mutable_point is ({}, {})", mutable_point.x, mutable_point.y); // 包含一个指针的可变元组 let mut mutable_tuple = (Box::new(5u32), 3u32); { // 解构 `mutable_tuple` 来改变 `last` 的值。 let (_, ref mut last) = mutable_tuple; *last = 2u32; } println!("tuple is {:?}", mutable_tuple); }
悬空引用(Dangling References)
悬空指针:一个指针引用了内存中的某个地址,而这块内存肯已经释放并分配给其他人使用了
在Rust里,编译器可以保证引用永远不是悬空引用
编译器将保证在引用离开作用域前数据不会离开作用域
rustfn main() { let r = dangle(); } fn dangle() -> &String { // ^ 悬空指针 let s = String::from("hello"); return &s; }
引用规则
- 在任何给定的时刻,只能满足下列条件之一
- 一个可变的引用
- 任意数量的不可变引用
- 引用必须一直有效
- 在任何给定的时刻,只能满足下列条件之一
十、切片
Rust的另外一种不持有所有权的数据类型:切片(slice)
字符串切片是指向字符串中一部分内容的引用
&String[开始索引..结束索引]前取后不取区间rustfn main() { let s = String::from("hello world!"); let word_index = first_string(&s); println!("{} {}", word_index, s) } fn first_string(s: &String) -> &str { // &str 是字符串切片的类型 let bytes = s.as_bytes(); let mut flag = s.len(); for (index, &item) in bytes.iter().enumerate() { if item == b' ' { flag = index; } }; // 字符串切片 // return &s[..flag]; // return &s[flag..]; // return &s[..]; //全部 return &s[0..flag]; }字符串字面值被直接存储在二进制程序中,&str是不可变的
使用&str作为参数类型,这样就可以同时接收String和&str类型的参数
fn first_string(s: &str) -> &str- 使用字符串切片,直接调用该函数
- 使用String,可以创建一个完整的String切片来调用该函数
定义函数时使用字符串切片来代替字符串引用会使我们的API更加通用,且不会损失任何功能
其它类型切片
rustfn main() { let a = [1, 2, 3, 4, 5]; let b = &a[..4]; println!("{b:?}") }
十一、struct
- struct, 结构体
- 自定义的数据类型
- 为相关联的值命名,打包==》有意义的组合
定义 struct
使用
struct关键字,并为整个 struct 命名在花括号内,为所有字段(Field)定义名称和类型,即使最后一个也有逗号
一旦struct的实例是可变的,那么实例中的所有字段都是可变的
ruststruct User {
username: String,
email: String,
age: u32,
sex: bool,
}
fn main() {
let username = String::from("lihua");
let email = String::from("xxx@email.com");
// 类似js可以简写同名
let user = User {
username,
email,
age: 18,
sex: true,
};
println!("{} {} {} {}", user.username, user.email, user.age, user.sex)
}struct 更新语法
基于某个struct实例创建一个新的实例的时候使用
ruststruct User {
username: String,
email: String,
age: u32,
sex: bool,
}
fn main() {
let username = String::from("lihua");
let email = String::from("xxx@email.com");
let user1 = User {
username,
email,
age: 18,
sex: true,
};
let user = User {
username: String::from("李华"),
..user1
};
println!("{} {} {} {}", user.username, user.email, user.age, user.sex)
}Tuple struct
可以定义类似tuple的struct,叫做tuple struct
Tuple struct 整体有名,里面的元素无名
ruststruct Point (i32, i32);
fn main() {
let point = Point(23, 47);
}Unit-Like Struct (没有任何字段)
可以定义没有任何字段的struct,叫做Unit-Like struct (因为与(),单元类型类似)
适用于需要在某个类型上实现某个trait,但是指针里面没有想要存储的数据
struct Empty
struct 数据的所有权
ruststruct User {
username: String,
email: String,
age: u32,
sex: bool,
}这里的字段使用了String而不是&str
- 该struct实例拥有其所有的数据
- 主要struct实例是有效的,那么里面的字段数据也是有效的
struct 里也可以存放引用(生命周期)
- 生命周期保证只要struct实例是有效的,那么里面的引用也是有效的
什么是struct
std::fmt::Displaystd::fmt::Debug#[derive(Debug)]{:?}{:#?}
rust// 派生与Debug实现添加打印
#[derive(Debug)]
struct Rect {
x: i32,
y: i32,
width: i32,
height: i32,
}
fn main() {
let a = Rect {
x: 0,
y: 0,
width: 10,
height: 10,
};
println!("{:?}", a);
// 有格式化输出
println!("{:#?}", a);
}struct 的方法
方法和函数类似
在impl 块里定义方法
方法的第一个参数是&self,也可以获得其所有权或可变借用。和其他参数一样
rust// 派生与Debug实现添加打印
#[derive(Debug)]
struct Rect {
x: i32,
y: i32,
width: i32,
height: i32,
}
// 定义方法
impl Rect {
fn area(&self) -> i32 {
return self.width * self.height;
}
fn move_to(&mut self, x: i32, y: i32) {
self.x = x;
self.y = y;
}
}
fn main() {
let mut a = Rect {
x: 0,
y: 0,
width: 10,
height: 10,
};
println!("{:?}", a);
a.move_to(20, 10);
// 有格式化输出
println!("{:#?} {}", a, a.area());
}方法调用的运算符
在调用方法时Rust根据情况自动添加
&、&mut、或者*,以便object可以匹配方法的签名下面两行效果相同
rustp1.distance(&p2);
(&p1).distance(&p2);关联函数
可以在 impl 快里定义不把self作为第一个参数的函数,他们叫关联函数(不是方法)
String::from()
- 关联函数通常用于构造器
::符号- 关联函数
- 模块创建的命名空间
rust// 派生与Debug实现添加打印
#[derive(Debug)]
struct Rect {
x: u32,
y: u32,
width: u32,
height: u32,
}
// 定义方法
impl Rect {
// 关联函数
fn square(size: u32) -> Rect {
Rect {
width: size,
height: size,
x: 0,
y: 0,
}
}
}
fn main() {
let a = Rect::square(10);
println!("{:?}", a)
}十二、枚举与模式匹配
枚举
枚举允许我们列举所有肯的值来定义一个类型
rust// IP地址:IPV4、IPV6 enum IpAddrKind { IPv4, IPv6, } fn main() { let user_ip = IpAddrKind::IPv4; }数据附加到枚举
通过struct
rustenum IpAddrKind { IPv4, IPv6, } struct IpAddr { kind: IpAddrKind, address: String, } fn main() { let user_net = IpAddr { kind: IpAddrKind::IPv4, address: String::from("127.0.0.1"), }; }通过枚举变体
- 不需要额外的struct
- 每个变体可以拥有不同的类型以及关联的数据量
rustenum IpAddrKind { IPv4(u8, u8, u8, u8), IPv6(String), } fn main() { let user_net = IpAddrKind::IPv4(127, 0, 0, 1); let user_net = IpAddrKind::IPv6(String::from("127.0.0.1")); }
枚举方法
使用impl关键字
rustenum IpAddrKind { IPv4(u8, u8, u8, u8), IPv6(String), } impl IpAddrKind { fn edit(&self) { println!("edit") } } fn main() { let user_net = IpAddrKind::IPv4(127, 0, 0, 1); user_net.edit() }
Option枚举
定义于标准库中
在 Prelude(预导入模块)中
描述了某个值肯存在(某种类型)或不存在的清空
Rust中没有Null
- Null 的概念有用:因为某种原因而变为无效或缺失的值
Rust中类似Null概念的枚举
Option<T>标准库中的定义
rustenum Option<T> { Some(T), None, }
如果类型不是
Option<T>那么就认为该值是一个有效值,否则则需要自行处理转为T类型take方法- 消耗原
Option的值 - 将原
Option设为None - 返回被取出的值的
Option
- 消耗原
rustlet mut option = Some(String::from("hello"));
let value = option.take();
// option 现在是 None
// value 是 Some("hello")模式匹配(match)
允许一个值与一系列模式进行匹配,并执行匹配的模式对应的代码
模式可以是字面值、变量名、通配符...
rustenum Coin { Penny, Nickel, Dime, Quarter, } fn main() { let a = Coin::Dime; println!("{}", value_in_cents(a)) } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } }绑定值的模式
匹配的分支可以绑定到被匹配的对象的部分值
rust#[derive(Debug)] enum UsState { Alabama, Alaska, } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let a = Coin::Quarter(UsState::Alabama); println!("{}", value_in_cents(a)) } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 } Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter(state) => { println!("State quarter from {:?}!", state); 25 } } }match 匹配必须穷举所有的可能值
rustfn main() { let a = Some(5); let b = plus_one(a); println!("{}", b.unwrap()) } fn plus_one(v: Option<i32>) -> Option<i32> { match v { // 不能缺少了None None => None, Some(i) => Some(i + 1), } }_通配符:替代其余没有列出的值rustfn main() { let a = 1; match a { 1 => println!("one"), 2 => println!("two"), _ => println!("other"), } }
if let处理只关心一种匹配而忽略其它匹配的情况
rustfn main() { let a = 1; match a { 1 => println!("one"), _ => println!("other"), } if let _a = 1 { println!("one"); } else { println!("other"); } }更少的代码,更少的缩进,更少的模板代码
放弃了穷举的可能
可以把
if let看作是match的语法糖可以搭配
else使用
十三、Package、Crate、Module
Rust的代码组织
- 代码组织主要包括
- 哪些细节可以暴露,哪些细节是私有的
- 作用域内哪些名称有效
- ...
- 模块系统
- Package(包):Cargo的特性,让你构建、测试、共享crate
- Crate(单元包):一个模块树,它可以产生一个library或可执行文件
- Module(模块)、
use:让你控制代码的住宅、作用域、私有路径 - Path(路径):为
struct、function或module等项命名的方式
Pacakage 和 Crate
- Crate 的类型:
- binary
- library
- Crate Root:
- 是源代码文件
- Rust 编译器从这里开始,组成你的 Crate 的根 Module
- Package:
- 包含一个
Cargo.toml,它描述了如何构建这些 Crates - 只包含 0-1 个
library crate - 可以包含任意数量的
binary crate - 但必须包含一个
crate(library或binary)
- 包含一个
bash~>cargo new my-project Created binary (application) `my-project` package
Cargo 的惯例
src/main.rsbinary crate的crate rootcrate名与package名相同
src/lib.rspackage包含一个library cratelibrary crate的crate rootcrate名与package名相同
Cargo 把
crate root文件交给 rustc 来构建library或binary一个 Package 可以同时包含
src/main.rs和src/lib.rs- 一个
binary crate, 一个library crate - 名称与 package 名相同
- 一个
一个 Package 可以有多个
binary crate- 文件放到
src/bin - 每个文件都是单独的
binary crate
- 文件放到
Crate 的作用
- 将相关给你组合到一个作用域内,便于在项目间共享
- 防止冲突
- 将相关给你组合到一个作用域内,便于在项目间共享
Module:
在一个 crate 内,将代码进行分组
增加可读性,易于复用
控制项目(item)的私有性,public、private
建立moudle
mod关键字- 可嵌套
- 可包含其它项(struct、enum、常量、trait、函数等)的定义
rust// src/lib.rs /* crate front_of_house hosting add_to_waitlist seat_at_table serving take_order serve_order take_payment */ mod front_of_house { mod hosting { fn add_to_waitlist() {} fn seat_at_table() {} } mod serving { fn take_order() {} fn serve_order() {} fn take_payment() {} } }src/main.rs和src/lib.rs叫做crate roots- 这两个文件(任意一个)的内容形成了名为 crate 的模块,位于整个模块树的根部
- 整个模块树在隐式的 crate 模块xia
路径 Path
为了在Rust的模块中找到某个条目,需要使用路径
路径的两种形式
- 绝对路径:从
crate root开始,使用 crate名 或 字面值crate - 相对路径:从当前模块开始,使用
self、super或当前模块的标识符
- 绝对路径:从
路径至少由一个标识符组成,标识符质检使用
::rustmod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} } } pub fn eat_at_restaurant() { crate::front_of_house::hosting::add_to_waitlist(); front_of_house::hosting::add_to_waitlist(); }私有边界(privacy boundary)
- 模块不仅可以组织代码,还可以定义私有边界
- 如果想把 函数 或 struct 等设为私有,可以将他放到某个模块中
- Rust 中私有的条目(函数,方法,struct,enum,模块,常量)默认是私有的
- 通过
pub关键字来将条目标记为公共的 - 父级模块无法访问子模块中的私有条目
- 子模块中可以使用所有祖先模块中的条目
super 关键字
用来访问夫模块路径中的路径,类似文件系统中的
..rustfn serve_order() {} mod back_of_house { fn fix_incorrect_order() { cook_order(); super::serve_order(); } fn cook_order() {} }
pub struct
- pub 放在 struct 前
- struct 是公共的
- struct 的字段默认是私有的
- struct 的字段需要单独设置 pub 来变成公有
rustmod back_of_house { pub struct Breakfast { pub toast: String, seasonal_fruit: String, } impl Breakfast { pub fn summer(toast: &str) -> Breakfast { Breakfast { toast: String::from(toast), seasonal_fruit: String::from("peaches"), } } } } pub fn eat_at_restaurant() { let mut meal = back_of_house::Breakfast::summer("Rye"); meal.toast = String::from("Wheat"); println!("I'd like {} toast please", meal.toast); // 私有字段无法访问 meal.seasonal_fruit = String::from("blueberries"); }- pub 放在 struct 前
pub enum
- pub 放在 enum 前
- enum 是公共的
- enum 的变体也都是公共的
rustmod back_of_house { pub enum Appetizer { Soup, Salad, } }- pub 放在 enum 前
use 关键字
可以使用
use关键字将路径导入到作用域内仍然遵守私有性原则
rustmod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} fn seat_at_table() {} } } use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); // 不可用是私有方法 hosting::seat_at_table(); }
使用
use来指定相对路径rustmod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} fn seat_at_table() {} } } use front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); // 不可用是私有方法 hosting::seat_at_table(); }use的习惯用法函数:将函数的父模块引入作用域(指定到父级)
use front_of_house::hosting;struct,enum, 其他:置顶完整路径(指定到本身)use front_of_house::hosting::Sex;当需要使用不同模块里的同名时(指定到父级)
as关键字as关键字可以为引入的路径指定本地别名use std::io::Result as IoResult
pub use重新导出名称使用
use将路径(名称)导入到作用域内后,该名称在此作用域内是私有的pub use重新导出条目引入作用域
该条目可以被外部代码引入到他们的作用域
pub use front_of_house::hosting;
使用外部包(package)
Cargo.toml 添加依赖的包(package)
https://crates.io/
use 将特定条目引入作用域
use rand::Rng;标准库(std)也被当做外部包
use std::collections::HashMap;
使用嵌套路径清理大量的use语句
rust// use std::io; // use std::cmp::Ordering; // use std::io::Write; use std::io::{self, Write}; use std::{cmp::Ordering};通配符
*use io::*模块拆分为不同的文件
- 模块定义时,如果模块名后变是
;,而不是代码块- rust 会从与模块同名的文件中加载内容
- 模块树的结构不会发生变化
rust// lib.rs mod front_of_house; pub use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); // 不可用是私有方法 // hosting::seat_at_table(); }rust// front_of_house.rs pub mod hosting;rust// front_of_house/hosting.rs pub fn add_to_waitlist() {} fn seat_at_table() {} pub enum Sex { Male, Female, }- 随着模块逐渐变大,该技术可以让你把模块的内容移动到其他文件中
- 模块定义时,如果模块名后变是
十四、常用的集合
全部存放在对内存上,无需确定他的大小
Vector
Vec<T>,叫做vector- 标准库提供
- 可以存储多个值
- 只能存储相同类型
- 值在内存中是连续存放的
创建Vector
rust// 创建空元素
let a: Vec<i32> = Vec::new();
// 带有初始值的
let b = vec![1, 2, 3];更新Vector
添加元素
rustlet mut b = Vec::new(); b.push(1);删除Vector
- 与其他struct一样,离开作用域后
- 就会被清理掉
- 私有元素也会被清理掉
- 与其他struct一样,离开作用域后
读取元素
rustfn main() { let v = vec![1, 2, 3, 4, 5]; // 索引 let third: &i32 = &v[2]; println!("The third element is {}", third); // get方法 match v.get(2) { Some(third) => println!("The third element is {}", third), None => println!("There is no third element."), } }所有权和借用的规则
不能在同一作用域内同时拥有可变和不可变引用
rustfn main() { let mut v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; // 添加后vector可能会改变存储位置,所以third引用会失效,导致异常 v.push(6); println!("The third element is {}", third) }
遍历Vector
rustfn main() { let v = vec![1, 2, 3, 4, 5]; for i in &v { println!("v={}", i) } } fn mut_vec() { let mut v = vec![1, 2, 3, 4, 5]; for i in &mut v { *i += 1; println!("v={}", i) } }使用 enum 来存储多种数据类型
- Enum 的变体可以附加不同类型的数据
- Enum 的变体定义在同一个enum 类型下
rust// #[derive(Debug)] enum SpreadsheetCell { Int(i32), Float(f64), Text(String), } fn main() { let row = vec![ SpreadsheetCell::Int(64), SpreadsheetCell::Float(3.14), // 避免字符串直接放到栈内存 SpreadsheetCell::Text(String::from("hello")), ]; for cell in row.iter() { match cell { SpreadsheetCell::Text(v) => { println!("Text {v}") } SpreadsheetCell::Int(v) => { println!("Int {v}") } SpreadsheetCell::Float(v) => { println!("Float {v}") } } } }
String
Rust 开发者经常会被字符串困扰的原因
- Rust倾向于暴露可能的错误
- 字符串数据结构复杂
- UTF-8 编码
字符串是什么
- Rust 的核心语言层面,只有一个字符串类型:字符串切片 str(或&str)
- 字符串切片:对存储在其他地方、UTF-8 编码的字符串的引用
- 字符串字面值:存储在二进制文件中、也是字符串切片
- String 类型
- 来自 标准库 而不是核心语言层面
- 可增长、可修改、可拥有
- UTF-8 编码
- 通常说的字符串是指 String 和 &str
- Rust 的标准库还包含了很多其他的字符串类型
- OsString
- OsStr
- CString
- CStr
- String(通常可获得所有权) 和 Str(通常可借用)
- 可存储不通编码的文本或在内存中以不同的形式展现
- Library crate(三方库)针对存储字符串可提供更多的
创建一个新的字符串(String)
由于String是字节切片,很多
Vec<T>的操作都可用于StringString::new()函数创建空字符串let mut s = String::new();使用初始值来创建String
to_string()方法,可用于实现了Display trait 的类型,包括字符串字面量
rustlet s:&str = "init"; let string:String = s.to_string();String::from() 函数,从字面值创建String
rustlet string = String::from("hello");
更新 String
- push_str() 方法:把一个字符串切片附加到 String
- push() 方法:摆一个字符附加到String
- 连接:+
- 类似使用了
fn add(self, s:&str)->String {...}- 标准库中的add方法使用了泛型
- 只能把&str添加到String
- 解引用强制转换(deref coercion)
- 类似使用了
format!宏
rustfn main() {
let mut string = String::from("hello");
// 添加字符串
string.push_str("world");
// 添加字符
string.push('l');
// 拼接
let s1 = String::from("hello, ");
let s2 = String::from("world!");
// String + &String, 此时s1没有所有权了 add(s:&str)=>String
let s3 = s1 + &s2;
let s4 = format!("{}-{}", s1, s2);
}对 String 按所以的形式进行访问
- 按所以语法访问String的某部分,会报错
- Rust的字符串不支持索引语法访问
String 的内部表示
- String 是对
Vec<u8>的包装- len() 方法
字节、标量值、字形簇(Bytes,Scalar Values,Grapheme Clusters)
Rust 有三种看待字符串的方式
- 字节
- 标量值
- 字形簇(最接近所谓的”字母“)
rust// 遍历 Strig fn main() { let a = String::from("你好"); // 字节 println!("字节方式"); for b in a.bytes() { println!("{}", b) } // 标量 println!("标量"); for c in a.chars() { println!("{}", c) } // 字形簇, 查找第三方库 }Rust 不允许对 String 进行索引的最后一个原因
- 索引操作应该消耗一个常量时间(O(1))
- 而 String 无法保证:需要遍历所有内容,来确定有多少个合法的字符
切割 String
可以使用【】和一个范围来创建字符串的切片
- 谨慎使用
- 如果切割时跨越了字符边界,程序就会 panic
rustfn main() { let a = String::from("你好时间"); // 前3个字节,utf-8 中文占3个字节 let b = &a[0..3]; println!("{b:?}") }
String 不简单
- Rust 选择将正确处理 String 数据作文所有Rust 程序的默认行为
- 必须在处理UTF-8数据之前投入更多的精力
- 可以防止在开发后期处理设计费ASCII字符的错误
HashMap
HashMap<K, V>
- 键值对的形式存储数据,一个键(Key)对应一个值(Value)
- Hash 函数:决定如何在内存中存放K和V
- 适用场景:通过K(任何类型)来寻找数据,而不是通过索引
创建HashMap
创建空
HashMap::new()方法rustuse std::collections::HashMap; fn main() { let mut scores: HashMap<String, i32> = HashMap::new(); scores.insert(String::from("1"), 1); }HashMap使用较少,不在Prelude(预导入)中
标准库对器支持较少,没有内置的宏来创建HashMap
数据存储在heap上
同构
- 所有K,V必须是同一类型
collect创建HashMap
- 在元素类型为Tuple的Vector上使用collect方法,可以组建一个HashMap
rustuse std::collections::HashMap; fn main() { let a = vec![ String::from("情出自愿"), String::from("事过无悔") ]; let b = vec![ 1, 2 ]; // 需要显式声明类型 // let dict: HashMap<&String, &i32> = a.iter().zip(b.iter()).collect(); let dict: HashMap<_, _> = a.iter().zip(b.iter()).collect(); println!("{}", dict[&String::from("情出自愿")]) }
HashMap 和所有权
对于实现了
Copy trait的类型(如i32),值会被复制到HashMap中对于拥有所有权的值(例如String),值会被移动,所有权会转移给HashMap
rustuse std::collections::HashMap; fn main() { let field_name = String::from("color"); let field_value = String::from("red"); let mut map = HashMap::new(); map.insert(field_name, field_value); }如果将值的引用插入到HashMap,值本身不会移动
- 在HashMap有效的期间,呗引用的值必须保持有效
rustuse std::collections::HashMap; fn main() { let field_name = String::from("color"); let field_value = String::from("red"); let mut map = HashMap::new(); map.insert(&field_name, &field_value); }
访问HashMap中的值
get 方法
- 参数:K
- 返回:
Option<&V>
rustuse std::collections::HashMap; fn main() { let field_name = String::from("color"); let field_value = String::from("red"); let mut map = HashMap::new(); map.insert(&field_name, &field_value); let v = map.get(&field_name); match v { Some(V) => { println!("value is {}", V) } None => { println!("this is None") } } }
遍历HashMap
for循环
rustuse std::collections::HashMap; fn main() { let field_name = String::from("color"); let field_value = String::from("red"); let mut map = HashMap::new(); map.insert(&field_name, &field_value); for (k, v) in &map { println!("{}: {}", k, v) } }
更新 HashMap
HashMap 大小可变
每个 K 同时只能对应一个 V
更新HashMap中的数据
- K已经存在,对应一个V
- 替换现有的V
- 保留现有的V,忽略新的V
- 合并现有的V和新的V
rustuse std::collections::HashMap; fn main() { let field_name = String::from("color"); let age = String::from("age"); let field_value = String::from("red"); let field_value2 = String::from("blue"); let mut map = HashMap::new(); map.insert(&field_name, &field_value); // 覆盖 map.insert(&field_name, &field_value2); // 新增 map.insert(&age, &field_value2); // 检查是否存在Key, 如果K存在,返回V的可变引用。不存在将方法参数作为K的新值作为K的新值插进去,返回V的可变引用 let e = map.entry(&age); // 如果不存在就插入 e.or_insert(&field_value); // 返回的是一个可变应用,操作前解引用可以修改HashMap中的值 *e += 1; println!("{map:?}") }- K已经存在,对应一个V
Hash函数
- 默认情况下,HashMap 使用加密功能强大的 Hash 函数,可以抵抗拒绝服务(Dos)攻击
- 不是最可用的最快的 Hash 算法
- 但具有更好的安全性
- 可以指定不同的 hasher 来切换到另一个函数
- hasher 是实现 BuildHasher trait 的类型
十五、错误处理
Rust 错误处理概述
- Rust的可靠性:错误处理
- 大部分情况下:在编译时提示错误,并处理
- 错误分类
- 可恢复
- 例如文件未找到,可再次尝试
- 不可恢复
- bug,例如索引超出范围
- 可恢复
- Rust 没有类似异常的机制
- 可恢复错误:
Result<T, E> - 不可恢复:
panic!宏
- 可恢复错误:
不可恢复的错误与 panic
当 panic! 宏执行
- 程序打印错误信息
- 展开(unwind)、清理调用栈(Stack)
- 退出程序
为应对 panic,展开或中止(abort)调用栈
- 默认情况下,当 panic 发生
- 程序展开调用栈(工作量大)
- Rust沿着调用栈往回走
- 清理每个遇到的函数中的数据
- 或立即中止调用栈
- 不进行清理,直接停止程序
- 内存需要系统(OS)进行自动清理
- 程序展开调用栈(工作量大)
- 默认情况下,当 panic 发生
想让二进制文件更小,把设置从“展开”改为“中止”
在Crago.toml中适当的profile部分设置 panic 为 abort
toml[package] name = "demo" version = "0.1.0" edition = "2021" [dependencies] rand = "^0.8.5" [profile.release] panic = "abort"
使用 panic! 产生的回溯信息
- panic! 可能出现在
- 我们写的代码中
- 我们所依赖的代码中
- 可通过调用 painc! 的函数的回溯信息来定位引起问题的代码
- 通过设置环境变量 RUST_BACKTRACE 可得到回溯信息
- 未来获取带有调试信息的回溯,必须启用调试符号(不带 --release)
Result 与可恢复的错误
Result 枚举
rustenum Result<T, E> {
Ok(T),
Err(E)
}T:操作成功情况下,Ok 变体里返回的数据的类型
E:操作失败情况下,Err 变体里返回的数据的类型
rustuse std::fs::File; fn main() { let f = File::open("./1.txt"); let f = match f { Ok(file) => file, Err(e) => panic!("Error opening file: {}", e) }; }匹配不同的错误
rustuse std::fs::File; use std::io::ErrorKind; fn main() { let f = File::open("./1.txt"); let f = match f { Ok(file) => file, Err(error) => match error.kind() { // 如果文件不存在,则创建文件 ErrorKind::NotFound => match File::create("./1.txt") { Ok(fc) => fc, Err(e) => panic!("Problem creating the file: {:?}", e), }, other_error => panic!("Problem opening the file: {:?}", other_error), } }; }- match 很有用,但是很原始
- 闭包(closure)
Result<T, E>又很多方法:- 他们接收闭包作为参数
- 使用 match 实现
- 使用会让代码更简洁
rustuse std::fs::File; use std::io::ErrorKind; fn main() { // unwrap 在错误时直接 panic! 相当于第一个例子 let f = File::open("./1.txt").unwrap(); let f = File::open("./1.txt"); // unwrap_or_else 函数当错误发生时,执行一个闭包,返回一个值 let f = f.unwrap_or_else(|error| match error.kind() { // 如果文件不存在,则创建文件 ErrorKind::NotFound => match File::create("./1.txt") { Ok(fc) => fc, Err(e) => panic!("Problem creating the file: {:?}", e), }, other_error => panic!("Problem opening the file: {:?}", other_error), }); }expect
和 unwrap 类似,但可以指定错误信息
rustuse std::fs::File; fn main() { let f = File::open("./1.txt").expect("无法打开文件 1.txt"); }
传播错误
- 在函数处处理错误
- 将错误返回给调用者
rustuse std::fs::File; use std::io::Read; fn read_file_string() -> Result<String, std::io::Error> { let f = File::open("./1.txt"); let mut f = match f { Ok(file) => file, Err(e) => return Err(e), }; let mut s = String::new(); match f.read_to_string(&mut s) { Ok(_) => Ok(s), Err(e) => Err(e), } } fn main() { let f = read_file_string(); match f { Ok(s) => println!("file string is: {}", s), Err(e) => println!("error is: {}", e), } }? 运算符:传播错误的一种快捷方式
rustuse std::fs::File; use std::io::Read; fn read_file_string() -> Result<String, std::io::Error> { let mut f = File::open("./1.txt")?; let mut s = String::new(); f.read_to_string(&mut s)?; Ok(s) } fn main() { let f = read_file_string(); match f { Ok(s) => println!("file string is: {}", s), Err(e) => println!("error is: {}", e), } }- 如果 Result 是 Ok:Ok 中的值就是表达式的结果,然后继续执行
- 如果 Result 是 Err:Err就是整个函数的返回值,就像使用了 return
? 与 from 函数
Trait std::convert:From上的 from 函数- 用于错误之间的转换
- 被 ? 所应用的错误,会隐式的被 from 函数处理
- 当 ? 调用 from 函数时
- 它所接收的错误类型会被转换为当前函数返回类型所定义的错误类型
- 前提是原始错误类型实现了转换到返回错误类型的from方法
- 用于:正对不同错误类型原因,返回同一种错误类型
rustuse std::fs::File; use std::io::Read; fn read_file_string() -> Result<String, std::io::Error> { let mut s = String::new(); File::open("./1.txt")?.read_to_string(&mut s)?; Ok(s) } fn main() { let f = read_file_string(); match f { Ok(s) => println!("file string is: {}", s), Err(e) => println!("error is: {}", e), } }? 只能用于返回值为Result的函数
? 运算符与main函数
- main函数的返回值类型是:()
- main 函数的返回类型也可以是:
Result<T, E> Box<dyn std::error:Error>是trait 对象- 可以理解为任何肯的错误类型
dyn(德来米)
rustuse std::fs::File; // Box<dyn std::error::Error> 可以理解为任何可能的错误类型 fn main() -> Result<(), Box<dyn std::error::Error>> { let file = File::open("data.txt")?; Ok(()) }
什么时候使用 panic
- 在定义一个可能失败的函数时,有限考虑返回 Result
- 否则就 panic
编写示例、原型代码,测试
可以使用 panic
- 演示某些概念 unwrap
- 原型代码:unwrap、expect
- 测试:unwrap、expect
比编译器掌握更多有用的信息
- 可以确定 Result 就是 OK: unwrap
错误处理的指导性建议
- 但代码最可能初遇损坏状态时,最好使用 panic
- 损坏状态(Bad state):某些假设、保证、约定或不可变性被打破
- 例如非法的值、矛盾的值或空缺的值被传入代码
- 以及下列中的一条
- 这种损坏并不是预期能够偶尔发生的事情
- 在此之后,代码处于这种状态无法运行
- 在使用的类型中没有一个好的方法来将这些信息(初遇损坏状态)进行编码
场景
- 调用代码,传入无意义的参数值:panic
- 调用外部不可控代码,返回非法状态,你无法修复:panic
- 如果失败可预期:Result
- 当你的代码对值进行操作,实现应该验证这些值:panic
为验证创建自定义类型
rustfn main() { loop { let guess = "32"; // 删除 guess 变量前后的空白字符解析为i32类型 let guess: i32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, }; if guess < 1 || guess > 100 { println!("请输入1到100之间的数字"); continue; } } }创建新的类型,把验证逻辑放到构造实例的函数里
rustpub struct Guess { value: i32, } impl Guess { pub fn new(value: i32) -> Guess { if value < 1 || value > 100 { panic!("Guess value must be between 1 and 100, got {}.", value); } Guess { value } } pub fn value(&self) -> i32 { self.value } } fn main() { loop { let guess = "32"; // 删除 guess 变量前后的空白字符解析为i32类型 let guess: i32 = match guess.trim().parse() { Ok(num) => num, Err(_) => continue, }; // 能创建成功就代表该值一定有效 let guess = Guess::new(guess); } }
十六、泛型
- 提高代码的复用能力
- 处理重复代码
- 泛型是具体类型或其它属性的抽象代替
- 你编写的代码不是最终的代码,而是一种模板,里面有一些“占位符”
- 编译器在编译时将“占位符”替换位具体的类型
Struct 定义中的泛型
ruststruct Point<T> {
x: T,
y: T,
}
struct Point2<T, U> {
x: T,
y: U,
}- 可以使用多个泛型的类型参数
- 太多类型参数:代码需要重组位多个更小的单元
Enum 定义中的泛型
rustenum Shape<T> {
Ok(T),
None,
}
enum Shape2<T, E> {
Ok(T),
Err(E),
}- 可以让枚举的变体持有泛型数据类型
方法定义中的泛型
ruststruct Shape<T> {
x: T,
y: T,
}
impl<T> Shape<T> {
fn x(&self) -> &T {
return &self.x;
}
}为 struct 或 enum 实现方法的时候,可在定义中使用泛型
注意
把T放在impl关键字后,表示在类型T上实现方法
只针对具体类型实现方法(其余类型没实现方法)
rustimpl Point<f32>
struct 里的泛型类型参数可以和方法的泛型参数不同
ruststruct Shape<T, U> { x: T, y: U, } impl<T, U> Shape<T, U> { fn mix<V, W>(&self, other: Shape<V, W>) -> Shape<V, W> { return Shape { x: other.x, y: other.y, } } }
泛型代码的性能
- 使用泛型的代码和使用具体类型的代码运行速度是一样的
- 单态化(monomorphization)
- 在编译时将泛型替换为具体类型的过程
rustfn main() {
let insteger =Some(5);
let float = Some(5.0);
}
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
// fn main(){
// let integer = Option_i32::Some(5);
// let integer = Option_f64::Some(5.0);
// }十七、Trait
Trait 告诉 Rust 编译器:
- 某种类型具有哪些并且可以与其它类型共享的功能
Trait 抽象的定义共享行为
Trait bounds (约束) 泛型类型参数指定为实现了特定行为的类型
Trait 与其它语言的接口 interface 类似,但存在区别
定义 Trait
Trait 的定义: 把方法签名放在一起,来定义实现某种目的所必须的一组行为
- 关键字
trait - 只有方法签名,没有具体实现
trait可以有多个方法,每个方法签名占一行,以;结尾- 实现该
trait的类型不许提供具体的方法实现
rusttrait Summary {
fn summarize(&self) -> String;
}在类型上实现 trait
与为类型实现方法类似
不同之处
impl xxx for Tweet {}- 在
impl的块里,需要对trait里的方法签名进行具体实现
lib.rsrustpub trait Summary { fn summarize(&self) -> String; } pub struct NewsArticle { pub headline: String, pub location: String, pub author: String, pub content: String, } impl Summary for NewsArticle { fn summarize(&self) -> String { format!("{}, by {} ({})", self.headline, self.author, self.location) } } pub struct Tweet { pub username: String, pub content: String, pub reply: bool, pub retweet: bool, } impl Summary for Tweet { fn summarize(&self) -> String { format!("{}: {}", self.username, self.content) } }mian.rsrustuse demo::{Summary, Tweet}; fn main() { let tweet = Tweet { username: String::from("horse_ebooks"), content: String::from("of course, as you probably already know, people"), reply: false, retweet: false, }; println!("1 new tweet: {}", tweet.summarize()); }只有当
trait在当前作用域才能使用实现的方法,如上main.rs中不引入Summary就不可以调用summarize方法
实现 trait 的约束
可以在某个类型上实现某个 trait 的前提条件是:
- 这个类型 或 这个
trait是在本地crate里定义的
无法为外部类型来实现外部的 trait
- 这个限制是程序属性的一部分(一致性)
- 孤儿机制:父类型不存在
- 此规则可以确保其他人不能破坏您的代码,反之亦然
- 如果没有这个规则,两个
crate可以为同一类型实现同一个trait,Rust 就不知道应该使用哪个实现了
默认实现
通过设置默认实现来为类型添加默认实现
rustpub trait Summary {
fn summarize(&self) -> String {
String::from("Read more...")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}默认方法可以调用 trait 中的其它方法,即使这些方法没有默认实现,,那么使用该方法就得实现对应的依赖方法
rustpub trait Summary {
fn summary_author(&self) -> String;
fn summarize(&self) -> String {
format!("Read more... author is {}", self.summary_author())
}
}无法从方法实现的重写实现里面调用默认实现,重写了该实现就会导致默认实现无效且不可调用
Trait 作为参数
impl Trait 语法:适用于简单情况
rust
pub trait Summary {
fn summary_author(&self) -> String;
fn summarize(&self) -> String {
format!("Read more... author is {}", self.summary_author())
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summary_author(&self) -> String {
self.author.to_string()
}
}
pub fn notify(item: impl Summary) {
println!("Breaking news! {}", item.summarize());
}
notify的 item 参数只能是实现了Summary的结构
Trait bound 语法:可用于复杂情况
impl Trait 语法是 Trait bound 的语法糖
rustpub fn notify1(item: impl Summary, item2: impl Summary) {
println!("Breaking news! {}", item.summarize());
}
pub fn notify<T: Summary>(item: T, item2: T) {
println!("Breaking news! {}", item.summarize());
}使用 + 指定多个 Trait bound
rustpub fn notify1(item: impl Summary + Display) {
println!("Breaking news! {}", item.summarize());
}
pub fn notify<T: Summary + Display>(item: T) {
println!("Breaking news! {}", item.summarize());
}Trait bound 使用 where 子句
在签名后指定 where 字句
rustpub fn notify1<T, U>(item: T, item2: U) -> String
where
T: Summary,
U: Summary,
{
format!("Breaking news! {}", item.summarize())
}Trait 作为返回类型
rustpub fn notify(s: &str) -> impl Summary {}
impl Trait只能返回确定的同一种类型,返回肯不同类型的代码会报错
rust// fn largest<T: PartialOrd + Copy>(list: &[T]) -> T {
// let mut largest = list[0];
//
// for &item in list.iter() {
// // 实现了 std::cmp::PartialOrd Trait 才能比较
// if item > largest {
// largest = item;
// }
// }
//
// largest
// }
fn largest<T: PartialOrd + Clone>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list.iter() {
// 实现了 std::cmp::PartialOrd Trait 才能比较
if item > &largest {
largest = item;
}
}
largest
}
fn main() {
let str_list = vec![String::from("hello"), String::from("world")];
let num_list = vec![1, 2, 3, 4, 5, 7, 8];
// String 在堆内存上没有实现 Copy Trait, 但是实现了 Clone Trait
println!("largest string is {}", largest(&str_list));
// i32 在栈内存上实现了 Copy Trait
println!("largest number is {}", largest(&num_list));
}使用 Trait Bound 有条件的实现方法
在使用泛型参数的 impl 块上使用 Trait Bound,我们可以有条件的为实现了特定 Trait 的类型来实现方法
rustuse std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
// 当 T 实现了 Display 与 PartialOrd 两个 Trait 他就具有cmp_display 方法
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}也可以为为实现了其它 Trait 的容易类型有条件的实现某个 Trait
为满足 Trait Bound 的所有类型上实现 Trait 叫做覆盖实现(blanket implementations)
rust// 标准库中为实现了 Display 的 Trait 添加了一个 to_string 方法
#[stable(featurn = "rust1", since = "1.0.0")]
impl<T: fmt::Display> ToString for T {
#[inline]
defalut fn to_string(&self) -> String {
todo!()
}
}十八、生命周期
Rust 中每个引用都有自己的生命周期
生命周期:让引用保持有效的作用域
大多数情况下:生命周期是隐式的、可被推断的
当引用的生命周期肯以不同的方式相互关联时:手动标注生命周期
避免悬垂引用(dangling reference)
- 生命周期的主要目标:避免悬垂引用
rustfn main() {
{
let r;
{
let x = 5;
r = &x;
}
// x被释放
println!("r: {}", r);
}
}借用检查器
Rust编译器的借用检查器:比较作用域来判断所有借用是否合法- 比较生命周期长度,长的引用短的就会编译错误
函数中的泛型生命周期
rustfn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}生命周期标注语法
- 生命周期的标注不会改变引用的生命周期长度
- 当指定了泛型生命周期参数,函数就可以结束带有如何生命周期的引用
- 生命周期的标注:描述了多个引用的生命周期间的关系,单不影响生命周期
标注语法
- 生命周期参数名
- 以
'开头 - 通常全小写且非常短
- 通常使用
'a
- 以
- 生命周期标注的位置
- 在引用的
&符号后 - 使用空格将标注和引用类型分开
- 在引用的
一个普通的引用 &i32
带有显式生命周期的引用 &'a i32
带有显式生命周期的可变引用 &'a mut i32
单个生命周期的标注本身没用意义
函数签名中的生命周期标注
- 泛型生命周期参数声明在函数名和参数列表之间的
<>中fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {return x}表示参数和返回值的生命周期都不能短于'a
'a生命周期为参数x和y中比较短的那个的生命周期的长度
反例: 由于string2的生命周期比较短所以为
'a, 但是当跳出该作用域时result还存在对string2的引用,所以生命周期编译异常
rustfn main() {
let string1 = String::from("abcd");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}深入了解生命周期
- 指定生命周期参数的方式依赖于函数所做的事
fn longest<'a>(x: &'a str, y: & str) -> &'a str {x}
- 函数只返回了x那么y的生命周期对于函数就没有意义,所以不需要为它指明生命周期
- 从函数返回一个引用时, 返回类型的生命周期参数需要与其中一个参数的生命周期匹配
- 如果返回的引用没有指向任何参数,那么它只能引用函数内创建的值
- 也就是悬垂引用: 该值在函数结束时就走出来作用域
这个时候当函数返回回去之后result的生命周期已经结束所以无法编译通过
rustfn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
let result = String::from("abc");
result.as_str()
}
// 这个时候需要返回内部变量可以选择返回 String 把函数内部值的所有权移交给函数调用者
fn longest2<'a>(x: &'a str, y: &'a str) -> String {
String::from("abc")
}Struct 定义中的声明周期标注
- Struct 里可包括
- 自持有类型(str)
- 引用: 需要在每个引用上添加生命周期标注
ruststruct ImportantExcerpt<'a> {
part: &'a str,
}
// first_sentence 的生命周期比 i 长所以编译成功
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.')
.next()
.expect("Could not find a '.'");
let i = ImportantExcerpt { part: first_sentence };
}生命周期的省略
- 每个引用都有生命周期
- 需要为使用生命周期的函数或 struct 指定生命周期参数
省略规则
- 在Rust引用分析中所编入的模式称为生命周期省略规则
- 这些跪着无需开发者来遵守
- 它们是一些特殊情况, 有编译器来考虑
- 如果你的代码符合这些情况, 那么就无需显式标注生命周期
- 生命周期省略跪着不会提供完整的判断
- 如果应用规则后, 引用的生命周期仍然模糊不清还是会编译错误
- 解决办法: 手动添加生命周期标注, 表明引用间的相互关系
输入、输出生命周期
- 函数/方法的参数: 输入生命周期
- 函数/方法的返回值: 输出生命周期
生命周期省略的三个规则
- 编译器使用3个规则在没有显示标注生命周期的情况下,来确定引用的生命周期
- 规则一应用于输入生命周期
- 规则二、三应用于输出生命周期
- 编译器应用完3个规则之后,仍然无法确定生命周期的引用则编译报错
- 这些规则适用于
fn定义和impl块
- 规则一: 每个引用类型的参数都有自己的生命周期
- 规则二: 如果只有一个输入生命周期参数, 那么该生命周期被赋予给所有的输出生命周期参数
- 规则三: 如果有多个输入生命周期参数,但其中一个是
&self或是&mut self(是方法), 那么 self 的生命周期会被赋给所有的输出生命周期参数
rust// 原始函数
fn first_word(s: &str) -> &str {}
// 规则一
fn first_wold<'a>(s: &'a str) -> &str {}
// 规则二
fn first_wold<'a>(s: &'a str) -> &'a str {} rust// 原始函数
fn long(x: &str, y: &str) -> &str = {}
// 规则一
fn long<'a, 'b>(x: &'a str, y: &'b str) -> &str = {}
// 是函数不是方法无法适配规则二、三所以需要手动标注
fn long(x: &str, y: &str) -> &str = {}方法定义中的生命周期标注
- 在
struct上使用生命周期实现方法, 语法和泛型参数的语法一样 - 在哪声明和使用的生命周期参数,依赖于:
- 生命周期参数是否和字段、方法的参数或返回值有关
struct字段的生命周期名- 声明在
impl关键字后 - 在
struct名后使用 - 这些生命周期是
struct类型的一部分
- 声明在
impl块内的方法签名中- 引用必须绑定于
struct字段引用的生命周期, 或者引用是独立的也可以 - 生命周期省略规则经常使得方法中的生命周期标注不是必须的
- 引用必须绑定于
ruststruct Image<'a> {
url: &'a str,
}
impl<'a> Image<'a> {
fn get_bit(&self) -> i32 { 3 }
// 规则三 alt生命周期赋给了self 省略返回 &'a str
fn get_url(&self, alt: &str) -> &str { self.url }
}
fn main() {
let image = Image { url: "https://example.com/image.jpg" };
let a = String::from("hello word");
let b = a.split('.').next().expect("no dot");
println!("{}", b)
}静态生命周期
'static是一个特殊的生命周期: 持续整个程序运行的时间- 例如: 所有的字符串字面值都拥有
'static生命周期let s: &'static str = "hello world"
- 例如: 所有的字符串字面值都拥有
- 为引用指定
'static生命周期前- 是否需要引用在整个生命周期内都存活
综合示例
rustuse std::fmt::Display;
fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a str
where T: Display, // T 可以被替换为任何实现了 Display trait 的类型
{
println!("Announcement! {}", ann);
if x.len() > y.len() {
x
} else {
y
}
}
fn main() {
}二十、编写自动化测试
编写和运行测试
测试(函数)
- 测试
- 函数
- 验证非测试代码的给你是否和预期一致
- 测试函数体(通常)执行的三个操作:
- 准备数据/状态
- 运行被测试代码
- 断言
Assert结果
解剖测试函数
- 测试函数需要使用
test属性attribute进行标注Attribute就是一段 Rust 代码的元数据- 在函数上加
#[test]可以把函数变为测试函数
运行测试
- 使用
cargo test命令运行所有测试函数- Rust 会构建一个
Test Runner可执行文件- 它会运行标注了
test的函数, 并报告其运行是否成功
- 它会运行标注了
- Rust 会构建一个
- 当使用
cargo创建library项目的时候, 会生成一个test module里面有一个test函数cargo new adder --lib创建一个library项目- 可以添加任意数量的
test module或函数
rustpub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}测试失败
- 测试函数
panic就表示失败 - 每个测试运行在一个新线程
- 当主线程看见某个测试线程挂掉了, 就标记为失败
rustpub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn it_works2() {
panic!("Make this test::fail")
}
}plaintextrunning 2 tests test tests::it_works ... ok test tests::it_works2 ... FAILED failures: ---- tests::it_works2 stdout ---- thread 'tests::it_works2' panicked at src\lib.rs:17:9: Make this test::fail note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace failures: tests::it_works2 test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
由于出现了
panic导致测试失败了
断言
使用 assert! 宏来检查测试结果
assert!宏, 来自标准库, 用来确定某个状态是否为truetrue测试通过false调用panic!, 测试失败
rust#[derive(Debug)]
pub struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
pub fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}使用 assert_eq! 和 assert_ne! 测试相等性
- 都来自标准库
- 判断两个参数是否 相等 或 不等
- 就是使用了
==和!=运算符的assert! - 断言失败会自动打印出两个参数的值
- 使用了
debug格式打印参数- 要求参数实现了
PartialEq和Debug Traits(所有的基本类型和标准库里的大部分类型都实现了)
- 要求参数实现了
- 使用了
rustpub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn if_adds_two(){
assert_eq!(4, add_two(2))
}
#[test]
fn not_adds_two() {
assert_ne!(5, add_two(2))
}
}plaintext自动打印错误值 ---- tests::not_adds_two stdout ---- thread 'tests::not_adds_two' panicked at src\lib.rs:16:9: assertion `left != right` failed left: 4 right: 4 note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
自定义错误消息
添加自定义错误消息
- 可以向
assert!、assert_eq!、assert_ne!添加可选的自定义消息- 这些自定义消息和失败消息都会打印出来
assert!第一个参数必填, 自定义消息作为第二个参数assert_eq!和assert_ne!前两个参数必填,自定义消息作为第三个参数- 自定义消息参数会被传递给
format!宏, 可以使用{}占位符
rustpub fn greeting(name: &str) -> String {
format!("Hello {}!", name)
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = greeting("world");
assert!(result.contains("kiss"), "错误值为:{}", result)
}
}使用 should_panic 检查恐慌
验证错误处理的情况
- 测试除了验证代码的返回值是否正确, 还需要验证代码是否如期的处理了发生错误的情况
- 可检验代码在特定的情况下是否发生了
panic should_panic属性(attribute)- 函数
panic: 测试通过 - 函数没有
panic: 测试失败
- 函数
rustpub struct Guess {
value: u32,
}
impl Guess {
pub fn new(value: u32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {}.", value);
}
Guess { value }
}
pub fn value(&self) -> u32 {
self.value
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn it_works() {
Guess::new(101);
}
}让 should_panic 更精确
- 为
should_panic属性添加一个可选的expected参数- 将检查
panic消息中是否包含所指定的文字
- 将检查
rustpub struct Guess {
value: u32,
}
impl Guess {
pub fn new(value: u32) -> Guess {
if value < 1 {
panic!("Guess value must be greater than or equal to 1, got {}.", value);
} else if value > 100 {
panic!("Guess value must be less than or equal to 100, got {}.", value)
}
Guess { value }
}
pub fn value(&self) -> u32 {
self.value
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "Guess value must be less than or equal to 100")]
fn it_works() {
Guess::new(101);
}
}测试中使用 Reault<T, E>
- 无需
panic通过返回Reault<T, E>作为返回类型编写测试- 返回
OK: 测试通过 - 返回
Err: 测试失败
- 返回
rust#[cfg(test)]
mod tests {
#[test]
fn it_works() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}此时不依靠
panic来做检查, 所以不要在Result<T, E>编写的测试上标注#[should_panic]
控制测试运行方式
- 改变
cargo test的行为: 添加命令行参数 - 默认行为
- 并行运行
- 所有测试
- 捕获 (不显示) 所有输出, 使读取与测试结果相关的输出更容易
- 测试通过的
println!就不会显示
- 测试通过的
- 命令行参数
- 针对
cargo test的参数: 紧跟cargo test后 - 针对测试可执行程序: 放在
--之后
- 针对
cargo test --help显示出后面可以跟的参数cargo test -- --help显示出--后面可以跟的参数
并行运行测试
- 运行多个测试: 默认使用过多个线程并行运行
- 运行快
- 确保测试之间
- 不会互相依赖
- 不依赖于某个共享状态 (环境、工作目录、环境变量等等)
--test-threads参数- 传递给二进制文件
- 不想以并行方式运行测试, 或相对现场数进行精选颗粒度控制
- 可以使用该参数后面跟上线程的数量
- 例子:
cargo test -- --test-threads=1
显式函数输出
- 默认, 如果测试通过,
Rust的test库会捕获所有打印到标注输出的内容 - 例如, 如果在被测试的代码中用到了
println!- 测试通过: 不会在终端看到打印的内容
- 测试不通过: 会看到打印的内容和失败信息
cargo test -- --show-output- 显示成功的输出
rustpub fn add_integers(a: i32, b: i32) -> i32 {
println!("Adding {} and {}", a, b);
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_add_integers() {
assert_eq!(add_integers(1, 2), 3);
}
#[test]
fn test_add_integers_negative() {
assert_ne!(add_integers(1, 2), 3);
}
}按照测试名称运行测试
按名称运行测试的子集
- 选择运行的测试: 将测试的名称 (一个或多个) 作为
cargo test的参数 - 运行单个测试: 参数只能传一个
cargo test test_add_integers - 运行多个测试: 指定测试名的一部分 (模块名
mod tests也可以)
忽略测试
忽略某些测试, 运行剩余测试
ignore属性 (attribule)
rustpub fn add_integers(a: i32, b: i32) -> i32 {
println!("Adding {} and {}", a, b);
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_add_integers() {
assert_eq!(add_integers(1, 2), 3);
}
#[test]
fn test_add_integers_negative() {
assert_eq!(add_integers(-1, -2), -3);
}
#[test]
#[ignore]
fn test_add_integers_zero() {
assert_eq!(add_integers(0, 0), 0);
}
}通过
cargo test -- --ignored来单独运行被忽略的测试
测试的组织
测试的分类
- 对测试的分类
- 单元测试
- 集成测试
- 单元测试
- 小, 专注
- 一次对以恶搞模块进行隔离的测试
- 可测试
private接口 (没有被pub的接口)
- 集成测试
- 在库外部, 和其他的外部代码一样使用你的代码
- 只能使用
public接口 - 可能在每个测试中使用到多个模块
单元测试
#[cfg(test)]标注约定在每个库文件中编写一个
tests模块来做测试用例
tests模块上的#[cfg(test)]标注- 只用运行
cargo test才编译和运行带代码
- 只用运行
- 集成测试在不同的目录, 它不需要
#[cfg(test)]标注 cfg:configuration配置- 告诉
Rust下面的条目只用在指定的配置选项下才被包含 - 配置选项
test: 由Rust提供, 用来百衲衣和运行测试- 只用
cargo test才会编译代码, 包括模块中的helper函数和#[test]标注的函数
- 只用
- 告诉
rust#[cfg(test)]
mod tests {
#[test]
fn it_works() {
assert_eq!(2 + 2, 4)
}
// 虽然没有 test 标记,但是它也会被编译
fn it_fails() {
assert_eq!(2 + 2, 5)
}
}测试私有函数
Rust允许测试私有函数
rustfn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use crate::add_two;
#[test]
fn it_works() {
assert_eq!(add_two(2), 4)
}
}集成测试
- 在
Rust里, 集成测试弯曲位于被测试库的外部 - 目的: 测试被测试库的多个部分是否能正确的一起工作
- 集成测试的覆盖率很重要
tests 目录
- 创建集成测试:
tests目录 tests目录下的每个测试文件都是一个单独的crate- 需要将测试库导入
- 无需标注
#[cfg(test)],tests目录被特殊对待
rust// tests/add_test.rs
use demo;
#[test]
fn test_add() {
assert_eq!(demo::add(1, 2), demo::add(2, 1));
}
运行指定的集成测试
- 运行一个指定的集成测试:
cargo test 函数名 - 运行某个测试文件内的所有测试:
cargo test --test 文件名
集成测试中的子模块
tests目录下每个文件被编译成单独的crate- 这些文件不共享行为 (与
src下的文件规则不同)
- 这些文件不共享行为 (与
tests目录下的 `凑到\
rust// tests/common/mod.rs
pub fn add_mod(a: i32, b: i32) -> i32 {
a + b
}针对 binary crate 的集成测试
- 如果项目是
binary crate, 只包含src/main.rs没有src/lib.rs- 不能在
tests目录下创建集成测试 - 无法把
main.rs的函数导入作用域
- 不能在
- 只用
library crate以为这独立运行
二十一、命令行程序
二进制程序关注点分离的指导性原则
- 将程序拆分为
main.rs和lib.rs, 将业务逻辑放入lib.rs - 当命令行解析逻辑少时放在
main.rs也行 - 当命令行解析逻辑变复杂时,需要将它从
main.rs提取到lib.rs
此处案例拆分后,留在 main 的功能
- 使用参数调用命令行解析逻辑
- 进行其他配置
- 调用
lib.rs中的run函数 - 处理
run函数可能出现的错误
测试驱动开发 TDD(Test-Driven Development)
- 编写一个会失败的测试,运行该测试,确保它是按照预取的原因失败
- 编写或修改代码,让新测试通过
- 重构刚刚添加或修改的代码,确保测试始终会通过
- 返回第一步,继续下一轮的开发
标准输出与标准错误
- 标准输出:
stdoutprintln!:可以使用cargo run > output.out
- 标准错误:
stderreprintln!:可以使用cargo run > output.out 2>&1
完整例子
项目结构
plaintextdemo ├─ Cargo.lock ├─ Cargo.toml ├─ output.txt ├─ test.txt └─ src ├─ lib.rs └─ main.rs
main.rs
rustuse demo;
use std::env;
fn main() {
// 如果有非ASCII字符,那么collect()会失败发生恐慌
let args: Vec<String> = env::args().collect();
// env::args_os() 返回OsString可以有非法ASCII字符
let query = demo::SearchConfig::new(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {}", err);
// code 为 1 表示异常退出, 0 为正常退出
std::process::exit(0)
});
if let Err(e) = demo::run(query) {
eprintln!("Application error: {}", e);
std::process::exit(0)
}
}lib.rs
rustuse std::{env, fs};
#[derive(Debug)]
pub struct SearchConfig {
pub query: String,
pub filename: String,
pub case_sensitive: bool,
}
#[derive(Debug)]
pub struct SearchResult<'a> {
pub line_number: usize,
pub line_text: &'a str,
}
impl SearchConfig {
pub fn new(args: &[String]) -> Result<SearchConfig, &'static str> {
if args.len() < 3 {
return Err("Not enough arguments");
}
// $env:CASE_INSENSITIVE=1 powershell 临时设置环境变量
// env::var读取环境变量, is_err() 如果Result错误,返回true, unwrap_or(default) Err时返回默认值
let case_sensitive = env::var("CASE_INSENSITIVE").unwrap_or(String::from("0"));
println!("case_sensitive: {}", case_sensitive);
Ok(SearchConfig {
query: args[1].to_string(),
filename: args[2].to_string(),
case_sensitive: case_sensitive == "1",
})
}
}
pub fn run(config: SearchConfig) -> Result<(), Box<dyn std::error::Error>> {
let file_text = fs::read_to_string(config.filename)?;
let results = if config.case_sensitive {
search(&config.query, &file_text)
} else {
search_case_insensitive(&config.query, &file_text)
};
for line in results {
println!("{:?}", line);
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<SearchResult<'a>> {
let mut results: Vec<SearchResult> = Vec::new();
let mut line_count = 0;
for line in contents.lines() {
line_count += 1;
if line.contains(query) {
results.push(SearchResult {
line_number: line_count,
line_text: line,
});
}
}
results
}
pub fn search_case_insensitive<'a>(query: &str, contents: &'a str) -> Vec<SearchResult<'a>> {
let mut results: Vec<SearchResult> = Vec::new();
let mut line_count = 0;
let query = query.to_lowercase();
for line in contents.lines() {
line_count += 1;
if line.to_lowercase().contains(&query) {
results.push(SearchResult {
line_number: line_count,
line_text: line,
});
}
}
results
}
#[cfg(test)]
mod tests {
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three,
Duct tape.";
let text = crate::search(query, contents);
println!("{:?}", text);
assert_eq!(1, text.len());
assert_eq!(
"safe, fast, productive.", text[0].line_text,
"search result {:?}",
text
);
}
#[test]
fn case_insensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three,
Duct tape.";
let text = crate::search_case_insensitive(query, contents);
println!("{:?}", text);
assert_eq!(2, text.len());
assert_eq!(
"safe, fast, productive.", text[0].line_text,
"search result {:?}",
text
);
assert_eq!("Duct tape.", text[1].line_text, "search result {:?}", text);
}
}二十二、函数式语言特性-迭代器和闭包
闭包
可以捕获器所在环境的匿名函数
- 是匿名函数
- 保持为变量、作为参数
- 可在一个地方创建闭包,然后在另一个上下文中调用闭包来完成运算
- 可以从其定义的作用域捕获值
例子-生成自定义运动计划的程序
- 算法的逻辑不是重点,重点是算法计算过程需要几秒钟时间
- 目标:不让用户发生不必要的等待
- 仅在必要时调用该算法
- 只调用一次
rustuse std::thread;
use std::time::Duration;
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}
fn generate_workout(intensity: i32, random_number: u32) {
let expensive_closure = |num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure(intensity));
println!("Next, do {} situps!", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Task a break today! Remember to stay hydrated!");
} else {
println!("Today, run for {} minutes!", expensive_closure(intensity));
}
}
}闭包的类型推断
- 闭包不要求参数和返回值的类型
- 闭包通常很短小,只在狭小的上下文中工作,编译器通常能推断出类型
- 可以手动标注
rustfn main() {
let my_fn = | num: u32 | -> u32 {
num
}
}函数和闭包的定义
rustfn add_one_v1 (x: u32) -> u32 { x+1 }
let add_one_v2 = | x: u32 | -> u32 { x+1 };
let add_one_v3 = | x | { x+1 };
let add_one_v4 = | x | x+1;缓冲器(Cacher)实现例子
使用 Fn Tarit 存储闭包函数(标注类型)
限制
Cacher实例假定针对不同的参数arg,value方法总会得到同样的值- 使用
HashMap代替单个值
- 使用
- 只能接收一个
u32类型的参数和u32类型的返回值
rustuse std::thread;
use std::time::Duration;
struct Cache<T>
where
T: Fn(i32) -> i32,
{
calculation: T,
value: Option<i32>,
}
impl<T> Cache<T>
where
T: Fn(i32) -> i32,
{
fn new(calculation: T) -> Cache<T> {
Cache {
calculation,
value: None,
}
}
fn value(&mut self, arg: i32) -> i32 {
match self.value {
Some(val) => val,
None => {
let v = self.calculation(arg);
self.value = v;
v
}
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}
fn generate_workout(intensity: i32, random_number: u32) {
let mut expensive_closure = Cache::new(|num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
});
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure.value(intensity));
println!("Next, do {} situps!", expensive_closure.value(intensity));
} else {
if random_number == 3 {
println!("Task a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure.value(intensity)
);
}
}
}HashMap 版
rustuse std::collections::HashMap;
use std::thread;
use std::time::Duration;
struct Cache<T>
where
T: Fn(i32) -> i32,
{
calculation: T,
value: HashMap<i32, i32>,
}
impl<T> Cache<T>
where
T: Fn(i32) -> i32,
{
fn new(calculation: T) -> Cache<T> {
Cache {
calculation,
value: HashMap::new(),
}
}
fn value(&mut self, arg: i32) -> i32 {
let result = self.value.get(&arg);
match result {
Some(v) => *v,
None => {
let v = (self.calculation)(arg);
self.value.insert(arg, v);
v
}
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}
fn generate_workout(intensity: i32, random_number: u32) {
let mut expensive_closure = Cache::new(|num| {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
});
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure.value(intensity));
println!("Next, do {} situps!", expensive_closure.value(intensity));
} else {
if random_number == 3 {
println!("Task a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure.value(intensity)
);
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn call_with_different_values() {
let mut c = Cache::new(|a| a);
assert_eq!(c.value(1), 1);
assert_eq!(c.value(2), 2);
assert_eq!(c.value(2), 2);
}
}闭包捕获环境
闭包可以捕获他们所在的环境
- 闭包可以访问定义它的作用域内的变量,而普通函数不可以
- 会产生内存开销
rustfn main() {
let x = 4;
let equal_to_x = |z| z == x;
let y = 4;
assert!(equal_to_x(y));
}闭包从所在环境捕获值的方式
与函数获得参数的三种方式一样
- 取得所有权:
FnOnce - 可变借用:
FnMut - 不可变借用:
Fn
- 取得所有权:
创建闭包时,通过闭包对环境值的使用,Rust 推断出具体使用哪个
trait- 所有的闭包都是实现了
FnOnce(逐级包含包含下面的Trait) - 没有移动捕获变量的实现了
FnMut - 无需可变访问捕获变量的闭包实现了
Fn
- 所有的闭包都是实现了
move 关键字
- 在参数列表前使用
move关键字,可以强制闭包取得它所使用的环境值的所有权- 当将闭包传递给新线程以移动数据使其归新线程所有时,此技术最为有用
rustfn main() {
let x = vec![1, 2, 3];
let equal_to_x = move |z| z == x;
// println!("{:?}", x); 没有所有权
let y = vec![1, 2, 3];
assert!(equal_to_x(y));
}最佳实践
- 当指定
Fn trait bound之一时,首先用Fn,基于闭包体里的情况,如果需要FnOnce或FnMut,编译器会再告诉你
迭代器
- 迭代器模式:对一系列项执行某些任务
- 迭代器负责:
- 遍历每一项
- 确定序列(遍历)合适完成
- Rust 的迭代器
- 懒惰性:除非调用消费迭代器的方法,否则迭代器本身没有任何效果
Iterator trait
所有迭代器都实现了该
traitIterator trait定义与标准库type Item和Self::Item定义了与该trait关联的类型- 实现
Iterator trait需要定义一个Item类型,他用于next方法的返回类型(迭代器的返回类型)
- 实现
仅要求实现一个方法
nextnext:- 每次返回迭代器中的一项
- 返回结果包裹在
Some里 - 迭代结束返回
None
rustpub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
} rustfn main() {
let x = vec![1, 2, 3];
let mut v1_iter = x.iter();
println!("val: {}", v1_iter.next())
}迭代方法
iter方法:在不可变引用上创建迭代器into_iter方法:创建的迭代器会获得所有权iter_mut方法:迭代可变的引用
消耗迭代器的方法
- 在标准库中,
Iterator trait有一些带默认实现的方法 - 其中有一些方法会调用
next方法- 实现
Iterator trait时必须实现next方法的原因之一
- 实现
- 调用
next的方法叫做 ”消耗型适配器“- 因为调用他们会把迭代器消耗尽
- 例如:
sum方法就会耗尽迭代器- 取得迭代器的所有权
- 通过反复调用
next,变量所有元素 - 每次迭代,把当前元素添加到一个总和里,迭代结束,返回总和
rustfn main() {
let x = vec![1, 2, 3];
let x_iter = x.iter();
// 类型标前或标后都可以
let x_sum: i32 = x_iter.sum::<i32>();
println!("val: {}", x_sum)
}产生其它迭代器的方法
Iterator trait上的另外一些方法叫做 ”迭代器适配器“- 把当前迭代器转换为不同类型的迭代器
- 可以通过链式调用使用多个迭代器适配器来执行复杂操作,这种调用可读性较高
- 例如:
map- 接收一个闭包,闭包作用域每个元素
- 产生一个新的迭代器
rustfn main() {
let x = vec![1, 2, 3];
let x_iter = x.iter().map(|item| item+1);
// 因为惰性所以使用 collect 方法收集迭代项
let y: Vec<_> = x_iter.collect();
println!("{:?}", y)
}filter方法:- 接受一个闭包
- 这个闭包在遍历迭代器的妹妹个元素时,返回bool类型
- 闭包返回为
true那么该元素会包含在filter产生的迭代器中
创建自定义迭代器
ruststruct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}
fn main() {
let mut counter = Counter::new();
if let Some(x) = counter.next() {
println!("{}", x);
} else {
println!("No more values!");
}
}循环与迭代器的性能
迭代器性能更好,在编译时有优化
如:消除迭代控制语句等
零开销抽象(Zero-Cost Abstraction)
- 使用抽象时不会引入额外的运行时开销
二十三、发布crate
crates.io
- 可以通过发布包共享代码库
crate的注册表在https://crates.io/- 他会分发已注册的包的源代码
- 主要托管开源代码
文档注释
- 文档注释:用于生成文档
- 生成
HTML文档 - 显式公共API的文档注释:如何使用 API
- 使用
/// - 支持
Markdown - 放置在呗说明条目之前
- 生成
cargo doc:生成 HTML文档命令- 他会运行
rustdoc工具(自带) - 把生成的文档放到
target/doc模块名下的index.html
- 他会运行
- 常用章节
#Examples:示例#Panics:函数肯发生panic的场景#Errors:如果函数返回Result,描述可能的错误种类,以及可导致错误的条件#Safety:如果函数处于unsafe调用,就应该解释函数unsafe的原因,以及调用者确保的使用前提
文档注释作为测试
文档注释中的示例会在
cargo test时当作测试执行
为包含注释的项添加文档注释
- 符号:
//! - 描述外层模块(不是描述之后的)
- 这类注释通常描述
crate和模块crate root(按照惯例src/lib.rs)- 一个模块呗,将
crate或模块作为一个整体进行记录
rust//! # demo crate
//!
//! `demo` is a simple demo crate.
/// 添加一的一个函数
/// # Examples
///
/// ```
/// use demo::add_one;
/// let arg = 6;
/// let add = add_one(arg);
/// assert_eq!(add, 7);
/// ```
///
pub fn add_one (x: i32) -> i32 {
x + 1
}pub use 导出方便使用的公共 API
- 问题:
crate的抽象结构在开发时对开发者很河里,但是对于使用者不方便- 开发者会把抽象结构才分为多层,使用者想找到这种深层次结构中的某个类型很费劲
- 例如:
- 麻烦:
demo::number_tools::add_module::AddType; - 方便:
demo::AddType;
- 麻烦:
- 解决办法:
- 不需要重新组织内部代码结构
- 使用
pub use:可以重新带出,创建一个内部私有结构不同的对外公共结构
rust//! # demo
//!
//! A crate for learning about rust
pub use self::kinds::*;
pub use self::utils::*;
pub mod kinds {
/// The primary colors according to the RGB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RGB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Mix two primary colors in equal amounts to create a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Green
}
}发布 Crates.io
- 发布
crate之前,需要在crates.io船舰账号并获得 API token - 运行命令:
cargo login <API token>- 通知
cargo把 API token 存储在本地的~/.cargo/credentials
- 通知
- API token 可以在官网撤销
- 配置
cargo.toml - 发布
cargo publish
toml[package]
# name 必须独一无二
name = "demo"
description = "简洁描述,出现在crate搜索结果里"
version = "0.1.0"
authors = ["YunHai"]
edition = "2024"
# 许可证 开源协议 http://spdx.org/licenses/ 多个许可使用 OR 隔开
license = "MIT"
crate一旦发布,就是永久性的:版本无法覆盖,代码无法删除,确保依赖该版本的项目可以继续正常工作
更新版本
- 修改配置文件中的
version再进行发布
撤回版本
- 不可以删除
crate之前的版本 - 但是可以防止新的项目依赖该版本:
yank(撤回)一个crate版本 yank意味着:- 所有已近产生
Cargo.lock的项目不会中断 - 任何将来生成的
Cargo.lock文件都不会使用被yank的版本
- 所有已近产生
cargo yank --vers 1.0.1撤回版本cargo yank --vers 1.0.1 --undo取消撤回版本
安装二进制 crate
从
crates.io安装二进制 crate
- 命令:
cargo install - 来源:
https://crates.io - 限制:只能安装具有二进制目标(
binary target)的crate - 二进制目标
binary target:是一个可执行文件- 由拥有
arc/main.rs或其他被指定为二进制文件的crate生成
- 由拥有
- 通常:
README中有关于crate的描述- 拥有
library target - 拥有
binary target - 两者皆有
- 拥有
- 需要在环境变量中,才可以直接运行
二十四、Cargo 工作空间(Workspaces)
cargo工作空间:帮助管理多个相互关联且需要协同开发的cratecargo工作空间是一套共享同一个Cargo.lock和输出文件夹的包
创建工作空间
- 有多种方式来组建工作空间例子:一个二进制
crate,两个库crate- 二进制
crate:main函数,依赖于其他两个库 - 其中一个库的
crate提供add_one函数 - 另一个库提供
add_two函数
- 二进制
创建工作空间并创建 toml 文件
bash(base) PS D:\CodeData\Rust> cd .\workspaces\
(base) PS D:\CodeData\Rust\workspaces> touch Cargo.toml
(base) PS D:\CodeData\Rust\workspaces> cargo new adder
(base) PS D:\CodeData\Rust\workspaces> cargo new add-one --libworkspaces/Cargo.toml
toml[workspace]
# 兼容新版 否则会警告
resolver = "2"
# 生命下面的工作crate
members = ["add-one", "adder"]
要使用依赖
crate需要声明
workspaces/adder/Cargo.toml
toml[package]
name = "adder"
version = "0.1.0"
edition = "2021"
[dependencies]
# 声明依赖关系
add-one = { path = "../add-one" }运行
crate使用cargo run -p adder
在工作空间中依赖外部 crate
工作空间只用一个
Cargo.lock文件,在工作空间的顶层目录,保证了工作空间内crate使用的依赖版本都相同
工作空间测试
全部测试
cargo test
单个 crate 测试
cargo test -p adder
工作空间发布
手动进入
crate逐个发布
二十五、自定义命令拓展 cargo
cargo被设计成可以使用子命令来拓展- 例如:如果 环境变量中的某个二进制是
cargo-something,你可以像子命令一样运行:cargo something - 查看自定义命令列表:
cargo --list - 优点:可以使用
cargo install来安装扩展,就像内置工具一样来运行
二十六、智能指针
指针:一个变量在内存中包含的是一个地址(指向其他数据)
Rust 中最常见的指针就是 “引用”
引用:
- 使用
& - 借用它指向的值
- 没有其余开销
- 最常见的指针类型
- 使用
智能指针
- 是指特殊的一些数据结构
- 行为和指针相似
- 有额外的元数据和功能
引用计数(reference counting)智能指针类型
- 通过记录所有者的数量,使用一份数据被多个所有者同时持有
- 并在没有任何所有者时自动清理数据
引用和智能指针的其他不同
- 引用:只借用数据
- 智能指针:很多时候都拥有它所指向的数据
智能指针例子
String和Vec<T>- 都拥有一篇内存区域,且运行用户对其操作
- 还拥有元数据(例如容量等)
- 提供额外的功能或保障(
String保障其数据是合法的UTF-8编码)
智能指针的实现
- 智能指针通常使用
struct实现,并且实现了Deref和Drop这两个trait Deref trait:允许智能指针struct的实例像引用一样使用Drop trait:允许自定义当指针示例走出作用域时的代码
常见的智能指针
Box<T>:在heap内存上分配值Rc<T>:启用多重所有权的引用计数类型Ref<T>和Ref<T>,通过RefCell<T>访问:在运行时而不是编译时强制借用规则的类型- 内部可变模式(
interior mutability pattern):不可变类型暴露出可修改内部值的 API - 引用循环(reference cycles):他们如何泄漏内存,以及如何防止其发生
使用 Box<T> 来指向 Heap 上的数据
Box<T>是最简单的智能指针- 运行在
heap上存储数据(而不是stack) stack上是指向heap数据的指针- 没有性能开销
- 没有其他额外功能
- 实现了
Deref trait和Drop trait
- 运行在
Box<dyn MyTrait>表示所有实现MyTraittrait的类型- 使用场景
- 在编译时,某个类型的大小无法确定。但使用该类型时,上下文却需要知道它的确切大小
- 当你有大量数据,想移交所有权,但需要确保在操作时数据不会被复制
- 使用某个值时,只关心它是否实现了特定的
trait而不关心它的具体类型
使用 Box<T> 在 heap 上存储数据
rustfn main() {
let b = Box::new(5);
println!("b = {}", b);
}使用 Box 赋能递归类型
- 在编译时, Rust 需要知道一个类型所占空间大小
- 而递归类型的大小无法在编译时确定
- 但
Box类型的大小确定 - 在递归类型中使用
Box就可以解决上述问题 - 函数式语言中的
Cons List- 来自 Lisp 语言的一种数据结构
- 其中的每个成员由两个元素组成
- 当前值
- 下一个元素
- 最后一个成员只包含一个
Nil值(终止标记), 没有下一个元素
Cons List并不是 Rust 的常用集合- 通常
Vec<T>是更好的选择
- 通常
- 创建一个
Cons List
rust// 无法确定大小无法运行
enum List { // [!code error]
Cons(i32, List), // [!code error]
Nil, // [!code error]
} // [!code error]- Rust 如何确定为枚举分配的空间大小
rust// 变体中占用最大的变体大小就是该枚举的大小 Quit 认为不占大小
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}使用
Box来获得确定大小的递归类型Box<T>是一个指针,Rust 知道他需要多少空间- 指针的大小不会具有与它指向的数据大小变化而变化
rustenum List { Cons(i32, Box<List>), Nil, }Box<T>- 只提供了 “间接” 存储和
heap内存分配的功能 - 没有其它额外功能
- 没有性能开销
- 适用于需要 “间接” 存储的场景,例如:
Cons List - 实现了
Deref trait(运行把值当作引用处理) 和Drop trait(当离开作用域时heap上的数据以及指针数据都会被自动清理)
- 只提供了 “间接” 存储和
Deref Trait
- 实现
Deref Trait使我们可以之定义解引用运算符*的行为 - 通过实现
Deref,智能指针可以像常规引用一样来处理
解引用运算符
- 常规引用是一种指针
rustfn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}把 Box<T> 当作引用
Box<T>可以代替上例中的引用
rustfn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}自定义智能指针
Box<T>被定义为拥有一个元素的tuple struct- 实现
Deref Trait- 标准库中的
Deref Trait要求实现一个deref方法- 该方法借用
self - 返回一个内部数据的引用
- 该方法借用
- 标准库中的
rustuse std::ops::Deref;
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
impl<T> Deref for MyBox<T> {
// 关联类型 Deref中用于表示解引用后值的类型
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, *y)
// 隐式的 *(y.deref())
}函数和方法的隐式解引用转化(Deref Coercion)
- 隐式解引用转化(
Deref Coercion)是为函数和方法提供的一种便捷特性 - 假设
T实现了Deref traitDeref Coercion可以把T的引用转化为T结果Deref操作后生成的引用
- 当把某类型的引用传递给函数或方法时,但他的类型与定义的参数类型不匹配
Deref Coercion就会自动发生- 编译器会对
deref进行一系列调用,来把他转为所需的参数类型- 编译时完成,运行时没有额外性能开销
rustuse std::ops::Deref;
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
impl<T> Deref for MyBox<T> {
// 关联类型
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
fn hello(name: &str) {
println!("Hello, {}!", name);
}
fn main() {
let m = MyBox::new(String::from("Rust"));
// &m &MyBox<String>
// deref &MyBox<String> -> &String
// deref &String -> &str
hello(&m);
hello(&(*m)[..]); // 没有deref的写法 [..]指示切片 ..指定范围
hello("Rust");
}解引用与可变性
- 可使用
DerefMut trait重载可变引用的*运算符 - 在类型和
trait在下列三种情况发生时,Rust 会执行deref coercion:- 当
T: Deref<Target=U>,允许&T转换为&U - 当
T: Deref<Target=U>,允许&mut T转换为&mut U - 当
T: Deref<Target=U>,允许&mut T转换为&U- 根据所有权规则 不可变引用 不能转为 可变引用
- 当
Drop Trait
- 实现
Drop Trait,可以自定义当值将要离开作用域时发生的动作- 例如:文件、网络资源释放等
- 任何类型都可以实现
Drop trait
Drop trait只要求你实现drop方法- 参数:对
self的可变引用
- 参数:对
Drop trait在预导入模块里(prelude)
ruststruct CustomSmartPtr {
data: String,
}
impl Drop for CustomSmartPtr {
fn drop(&mut self) {
println!("Dropping CustomSmartPtr with data `{}`!", self.data)
}
}
fn main() {
let _a = CustomSmartPtr {
data: String::from("my stuff"),
};
let _b = CustomSmartPtr {
data: String::from("other stuff"),
};
println!("CustomSmartPtr created.");
}使用 std::mem::drop 来提前 drop 值
- 很难直接禁用自动的
drop功能,也没必要Drop trait的目的就是进行自动的释放处理逻辑
- Rust 也不允许手动调用
Drop trait的drop方法 - 但可以调用标准库的
std::mem::drop函数,来提前drop值(在预导入模块中)
ruststruct CustomSmartPtr {
data: String,
}
impl Drop for CustomSmartPtr {
fn drop(&mut self) {
println!("Dropping CustomSmartPtr with data `{}`!", self.data)
}
}
fn main() {
let a = CustomSmartPtr {
data: String::from("my stuff"),
};
drop(a); // 手动释放,不会出现重复释放
let _b = CustomSmartPtr {
data: String::from("other stuff"),
};
println!("CustomSmartPtr created.");
}Rc<T> 引用计数智能指针
Python 垃圾回收机制
- 有时一个值会有多个所有者
- 为了支持多重所有权:
Rc<T>reference couting(引用计数)- 追踪所有到值的引用
- 0个引用:该值可以被清理掉
使用场景
需要在
heap上分配数据,这些数据被程序的多个部分读取(只读),但在编译时无法确定那个部分最后使用完这些数据Rc<T>只能用于单线程场景Rc<T>不在预导入模块(prelude)Rc::clone(&a)函数:增加引用计数Rc::strong_count(&a)获得当前强引用计数的值Rc::weak_count函数:弱引用
例子
- 两个
List共享 另一个List的所有权
- 两个
rustenum List {
Cons(u32, Rc<List>),
Nil,
}
use std::rc::Rc;
fn main() {
let a = Rc::new(List::Cons(1, Rc::new(List::Cons(2, Rc::new(List::Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
// a.clone(); 可能导致深拷贝
// Rc::clone(&a); 增加计数器
let _b = List::Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let _c = List::Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a))
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}Rc::clone() 与 类型的 clone() 方法
Rc::clone()增加引用,不会执行数据的深度拷贝操作- 类型的
clone()很多会执行数据的深度拷贝操作
Rc<T>
Rc<T>通过不可变引用,使你可以在程序不同部分之间共享只读数据- 可变引用会导致数据竞争
RefCell<T> 和内部可变性
内部可变性
- 内部可变性是 Rust 的设计模式之一
- 它允许在支持有不可变引用的前提下对数据进行修改
- 数据结构中使用了
unsafe代码来绕过 Rust 正常的可变性和借用规则
- 数据结构中使用了
RefCell<T>
- 与
Rc<T>不同,RefCell<T>类型代表了其持有数据的唯一所有权
RefCell<T> 与 Box<T> 的区别
- 借用规则
- 在任何给定的时间内,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用
- 引用总是有效的
Box<T> |
RefCell<T> |
|---|---|
| 编译时强制代码遵循借用规则 | 只在运行时检查借用规则 |
| 否则会出现错误 | 否则会触发 panic |
借用规则在不同阶段进行检查的比较
| 编译时 | 运行时 |
|---|---|
| 尽早暴露问题 | 问题暴露延后,甚至到生产环境 |
| 没有任何运行时开销 | 因借用计数产生些许性能损失 |
| 对大多数场景是最佳选择 | 实现某些特定的内存安全场景(不可变环境中修改自身数据) |
| Rust 的默认行为 |
RefCell<T>
- 与
Rc<T>相似,只能用于单线程场景
选择 Box<T>、Rc<T>、RefCell<T> 的依据
Box<T> |
Rc<T> |
RefCell<T> |
|
|---|---|---|---|
| 同一数据的所有者 | 一个 | 多个 | 一个 |
| 可变性、借用检查 | 可变、不可变借用(编译时检查) | 不可变借用(编译时检查) | 可变、不可变借用(运行时检查) |
即便
RefCell<T>本身不可变,但任能修改其中存储的值
内部可变性:可变的借用一个不可变的值
rustpub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
// 需要 '&mut self' 来改变 'sent_messages' 向量, 但是功能定义时这个引用定义时不是可变的
// 改为 'RefCell' 内部可变性时 使用 '&self' 就可以操作
fn send(&self, message: &str) {
// borrow_mut() 返回一个可变引用
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
// borrow() 返回一个不可变引用
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}使用 RefCell<T> 在运行是记录借用信息
- 两个方法(安全接口)
borrow方法- 返回智能指针
Ref<T>,它实现了Deref
- 返回智能指针
borrow_mut方法- 返回智能指针
RefMut<T>,它实现了Deref
- 返回智能指针
RefCell<T>会记录当前存在多少个活跃的Ref<T>和RefCell<T>智能指针:- 每次调用
borrow不可变借用计数加一 - 任何一个
Ref<T>的值离开作用域被释放时,不可变借用计数减一 - 每次调用
borrow_mut可变借用计数加一 - 任何一个
RefMut<T>的值离开作用域被释放时,可变借用计数减一
- 每次调用
- 以此技术来维护借用检查规则
- 任何一个给定时间内,只允许拥有多个不可变借用或一个可变借用
Rc<T> 和 RefCell<T> 结合使用实现拥有多重所有权的可变数据
rust#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
// 多重所有权的可变引用
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
// Rc智能指针的引用计数 一个不可变引用 值还是 value 内
// 通过 RefCell::borrow_mut() 获取可变引用 此时可以修改 value
// 结构体 List 的每个元素都拥有对 value 的可变引用 所以值会随着 value 的改变而改变
*value.borrow_mut() += 10;
println!("a after = {:?}", a);
println!("b after = {:?}", b);
println!("c after = {:?}", c);
}
其它内部可变性的类型
Cell<T>通过复制来访问数据Mutex<T>通过跨线程情形下的内部可变性模式
循环引用可导致内存泄漏
Rust 肯发生内存泄漏
- Rust 的内存安全机制可以保证很难发生内存泄漏,但是不是不可能
- 例如使用
Rc<T>和RefCell<T>就可能创造出循环引用,从而发生内存泄漏- 每个项的引用数量不会变成0,值也不会被处理掉
rustuse std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
List::Cons(_, item) => Some(item),
List::Nil => None,
}
}
}
fn main() {
let a = Rc::new(List::Cons(5, RefCell::new(Rc::new(List::Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(List::Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail())
}
防止内存泄漏解决办法
- 依靠开发者来保证,不依靠 Rust
- 重新组织数据结构:一些引用来表达所有权,一些引用不表达所有权
- 循环引用中的一部分具有所有权关系,另一部分不涉及所有权关系
- 只有持有所有权的指向关系才影响值的清理
防止循环引用把 Rc<T> 换成 Weak<T>
Rc::clone为Rc<T>实例子的strong_count加一,Rc<T>的实例只有在strong_count为零的时候才会被清理Rc<T>实例通过调用Rc::downgrade方法可以创建值的Weak Reference(弱引用)- 返回类型是
Weak<T>(智能指针) - 调用
Rc::downgrade会为weak_count加一
- 返回类型是
Rc<T>使用weak_count来追踪存在多少Weak<T>weak_count不为零并不影响Rc<T>实例的清理
Strong VS Weak
Strong Reference(强引用)是关于任何分享Rc<T>实例的所有权Weak Reference(弱引用)并不表述上诉意思- 使用
Weak Reference并不会创建循环引用- 当
Strong Reference数量为零的时候,Weak Reference会自动断开
- 当
- 在使用
Weak<T>前,需保证它指向的值仍然存在- 在
Weak<T>实例上调用upgrade方法,返回Option<Rc<T>>
- 在
rustuse std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf)
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
// 强引用 leaf,leaf 的父节点为 branch
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
// 弱引用 branch,branch 的父节点为 leaf
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf)
);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch)
);
}
// 走出作用域 释放 branch 弱引用, leaf 的强引用
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf)
);
}二十七、无畏并发
并发
Concurrent(并发):程序的不同部分之间独立的执行Parallel(并行):程序的不同部分同时运行- Rust 无畏并发:语序你编写没有细微 Bug 的代码,并在不引入新 Bug 的情况下易于重构
- 这里的并发泛指
concurrent与parallel
进程与线程
- 大部分 OS 中,代码运行在进程(process)中,OS 同时管理多个进程
- 在程序中,各独立部分可以同时运行,运行这些独立部分的就是线程(thread)
- 多线程运行:
- 提示性能表现
- 增加复杂度:无法保障各线程的执行顺序
多线程可导致的问题
- 竞争状态,线程一不一致的顺序访问数据或资源
- 死锁,两个线程彼此等待对方使用完所持有的资源,线程就无法继续
- 只在某些情况下发生的 Bug,很难可靠的复制现象和修复
实现线程的方式
- 通过调用 OS 的 API 来创建线程:1:1模型(一个操作系统的线程:一个程序里的线程)
- 需要较小的运行时
- 语言自己实现的线程(绿色线程):M:N模型(M个绿色线程:N个系统线程)
- 需要更大的运行时
- Rust:需要权衡运行时的支持
- Rust 标准库仅提供 1:1 模型的线程
通过 spawn 创建新线程
- 通过
thread::spawn函数可以创建新的线程- 参数:一个闭包(在新线程里运行的代码)
rustuse std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_secs(1));
}
});
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_secs(1));
}
// 不论子线程是否结束都会结束
}通过 join Handle 来等待所有线程的完成
thread::spawn函数的返回值是JoinHandleJoinHandle持有值的所有权- 调用其
join方法,可以等待对应的其它线程的完成
- 调用其
rustuse std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_secs(1));
}
});
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_secs(1));
};
handle.join().expect("thread panicked");
// handle.join().unwrap();
}使用 move 闭包
move闭包通常和thread:spawn一起使用,它允许你使用其它线程的数据- 创建线程时,把值的所有权从一个线程转移到另一个线程
rustuse std::thread;
fn main() {
let value = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("{:?}", value);
});
// 不使用 move 只给值的引用就会导致出现异常,例如:
// 此时线程还没结束还保留着对值的引用,但是值已经销毁
// drop(value);
handle.join().unwrap();
}使用消息传递跨线程传递数据
消息传递
- 一种很流行且能保证安全的并发的技术就是:消息传递
- 线程(或 Actor)通过本次发送消息(数据)来进行通信
- Go:不要用共享内存来通信,要用通信来共享内存
- Rust:
Channel(标准库提供)
Channel
Channel包含:发送端、接收端- 调用发送端的方法,发送数据
- 接收端会检查和接受到达的数据
- 如果发送端、接收端中容易一端被丢弃,那么
Channel就 “关闭” 了
创建 Channel
- 使用
mpsc::channel函数来创建Channelmpsc表示multiple producer, single consumer(多个生产者、一个消费者)- 返回一个
tuple(元组):里面元素分别是发送端、接收端
rustuse std::thread;
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
let handle = thread::spawn(move || {
// 必须有通道所有权才能发送消息
tx.send("Hello World!").unwrap();
});
let receiver = rx.recv().unwrap();
println!("Received {}", receiver);
}发送端 send 方法
参数: 想要发送的数据
返回:
Result<T, E>- 如果有问题(例如接收端已经被丢弃),就返回一个错误
接收端的方法
- recv 方法:阻塞当前线程执行,直到
Channel中有值被送来- 一旦有值收到,就会返回
Result<T, E> - 当发送端关闭,就会收到一个错误
- 一旦有值收到,就会返回
try_recv方法:不会阻塞- 立即返回
Result<T, E>- 有数据到搭配返回 OK,里面包含着数据
- 否则,返回错误
- 通常会使用循环来检查
try_recv的结果
- 立即返回
Channel 和所有权转移
- 所有权在消息传递中非常重要:能帮你编写安全、并发的代码
rustuse std::thread;
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
let handle = thread::spawn(move || {
// 必须有通道所有权才能发送消息
let val = String::from("Hi Rust");
tx.send(val).unwrap();
// val 所有权被移动到通道
println!("Send: {}", val)
});
let receiver = rx.recv().unwrap();
println!("Received {}", receiver);
}- 发送多个值,看到接收者在等待
rustuse std::thread;
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
let handle = thread::spawn(move || {
for i in 1..=5 {
println!("Sending {}", i);
tx.send(i).unwrap();
thread::sleep(std::time::Duration::from_secs(1));
}
});
// 当把 rx 当作迭代器时,它将阻塞(不用调用recv),直到有新的消息到达。
for received in rx {
println!("Got: {}", received);
}
handle.join().unwrap();
}- 通过克隆来创建多个发送者
rustuse std::thread;
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
let tx2 = mpsc::Sender::clone(&tx);
thread::spawn(move || {
for i in 1..=5 {
let msg = format!("Message from thread 1: {}", i);
tx1.send(msg).unwrap();
}
});
thread::spawn(move || {
for i in 6..=10 {
let msg = format!("Message from thread 2: {}", i);
tx2.send(msg).unwrap();
}
});
thread::spawn(move || {
tx.send("Final message".to_string())
});
for msg in rx {
println!("{}", msg);
}
}共享状态的并发
使用共享来实现并发
- Go 语言名言:==不要用共享内存来通信==,要用通信来共享内存。
- Rust 支持通过共享状态来实现并发。
Channel类似单所有权:一旦将值的所有权转移至Channel,就无法继续使用它
使用 Mutex 来保证每次只允许一个线程来访问数据
Mutex是mutual exclusion(互斥锁)的简写- 在同一时刻,
Mutex只允许一个线程来访问某些数据 - 访问数据
- 线程必须先获取互斥锁(lock)
lock数据结构是mutex的一部分,它能跟踪谁对数据拥有独占访问权
mutex通常被描述为:通过锁定系统来保护它所持有的数据
- 线程必须先获取互斥锁(lock)
Mutex 的两条规则
- 在使用数据之前,必须尝试获取锁(lock)
- 使用完
mutex所保护的数据,必须对数据进行解锁,以便其他线程可以获取锁
Mutext<T> 的 API
- 通过
Mutex::new(Data)来创建Mutex<T>Mutex<T>是一个智能指针
- 访问数据前,通过
lock方法获取锁- 会阻塞当前线程
lock肯会失败- 返回的是
MutexGuard(智能指针,实现了Deref和Drop)
rustuse std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
let mut num = m.lock().unwrap();
*num = 6;
}
println!("m = {:?}", m);
}使用 Arc<T> 来进行原子引用计数
Arc<T>和Rc<T>类似,它可以用于并发场景- A:
atomic:原子的
- A:
- 需要牺牲性能为代价才能使用
Arc<T>和Rc<T>的 API 是相同的
多线程共享 Mutex<T>
rustuse std::sync::{Mutex, Arc};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}RefCell<T> / Rc<T> VS Mutex<T> / Arc<T>
Mutex<T>提供了内部可变性,和Cell家族一样- 使用
RefCell<T>来改变Rc<T>里面的内容 - 使用
Mutex<T>来改变Arc<T>里面的内容 - 注意:
Mutex<T>有死锁的风险
通过 Send 和 Sync Trait 来拓展并发
- Rust 语言的并发特性较少,目前的并发都来自标准库(而不是语言本身)
- 无需局限于标准库的并发,可以自己实现并发
- 在 Rust 语言中有两个并发概念
std::marker::Sync和std::marker::Send这两个 Trait
Send :允许线程间转移所有权
- 实现
Send trait的类型可在线程间转移所有权 - Rust 中几乎所有类型都实现了
Send- 但
Rc<T>没有实现Send,它只用于单线程场景
- 但
- 任何完全由
Send类型组成的类型也被标记为Send - 除了原始指针之外,几乎所有类型都是
Send
Sync :允许从多线程访问
- 实现
Sync的类型可以安全的被多个现场引用 - 如果
T是Sync,那么&T就是Send- 引用可以被安全的送往另一个线程
- 基础类型都是
Sync - 完全由
Sync类型组成的类型也是SyncRc<T>不是Sync的RefCell<T>和Cell<T>家族也不是Sync的Mutex<T>是Sync的
手动实现
Send和Sync是不安全的,需要特别严谨才能确保安全性
二十八、面向对象编程特性
面向对象语言的特性
Rust 是面向对象编程语言吗?
- Rust 受到多种编程范式的影响,包括面向对象
- 面向对象通常包含以下特性:命名对象、封装、继承
对象包含数据和行为
- “设计模式四人帮” 在 《设计模式》 中给面向对象的定义:
- 面向对象的程序由对象组成
- 对象包装了数据和操作这些数据的过程,这些过程通常被称做方法或操作
- 基于此定义:Rust 是面向对象的
struct、enum包含数据impl块为之提供了方法- 但带有方法的
struct、enum并没有称为对象
封装
调用对象外部的代码无法直接访问对象内部的实现细节,唯一可以与独秀想进行交互的方法就是通过它公开的 API
- Rust:
pub关键字
rustpub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn new() -> Self {
AveragedCollection {
list: vec![],
average: 0.0,
}
}
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
None => None,
Some(value) => {
self.update_average();
Some(value)
}
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}继承
使对象可以沿用另外一个对象的数据和行为,且无需重复定义相关代码
- Rust:没有继承
- 使用继承的原因
- 代码复用
- Rust:默认
trait方法来进行代码共享
- Rust:默认
- 多态
- Rust:泛型和
trait约束(限定参数化多态bounded parametric)
- Rust:泛型和
- 代码复用
- 很多新语言都不适用继承作为内置的程序设计方案
使用 trait 对象来存储不同类型的值
创建一个 GUI 工具
- 他会遍历某个元素的列表,依次调用元素的
draw方法进行绘制- 例如:
Button、TextField等元素
面向对象语言中:
- 定义一个父类
Component父类,里面定义了draw方法 - 定义
Button、TextField等类,继承自Component类
为共有行为定义一个 trait
- Rust 避免将
struct或enum称为对象,因为他们与impl块是分开的 trait对象有些类似与其他语言中的对象- 它们某种程度上组合了数据与行为
trait对象与传统对象不同的地方- 无法为
trait对象添加数据
- 无法为
trait对象被专门用于抽象某些共有行为,它没其它语言中的对象那么通用
rust// 使用 trait 配合 Box 分配内存,dyn 来表示实现trait的类型(动态)
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
// 使用泛型只能表示一种,例如当T为Button时只能放入Button
/**
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl <T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
**/Trait 对象执行的是动态派发
- 将
trait约束作用域泛型时,Rust编译器会执行单态化- 编译器会为我们用来替换泛型类型参数的每一个具体类型生成对应函数和方法的非泛型实现
- 通过单态化生成的代码会执行静态派发(
static dispatch),在编译过程中确定调用的具体方法 - 动态派发(
dynamic dispatch)- 无法在编译过程中确定你调用的究竟是哪一种方法
- 编译器会产生额外的代码一边在允许时找出希望调用的方法
- 使用
trait对象,会执行动态派发- 产生运行时开销
- 阻止编译器内联方法代码,是的部分优化操作无法进行
Trait 对象必须保证对象安全
- 只能把满足对象安全(
object-safe)的trait转化为trait对象 - Rust 采用一系列规则来判定某个对象是否安全,只需记住两条规则
- 方法返回类型不是
Self - 方法中不包含任何泛型类型参数
- 方法返回类型不是
rustpub trait Clone {
fn clone(&self) -> Self;
}
pub struct Screen {
pub component: Vec<Box<dyn Clone>>, // [!code error] 此时 Clone 不是安全的 Trait 所以无法使用 dyn Clone
}
实现面向对象的设计模式
状态模式
state pattern是一种面向对象设计模式,一个值拥有的内部状态有数个状态对象(state object)表达而成,而值的行为则随着内部状态的改变而改变
使用状态模式意味着
- 业务需求变化时,不需要修改持有状态的值的代码,或使用这个值的代码
- 只需要更新对象内部的代码,一边改变其规则,或者增加一些新的状态对象
rust// lib.rs
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
// 在当前内容上添加内容
self.content.push_str(text);
}
pub fn content(&self) -> &str {
// 调用 trait 上的 content 之后发布后才有内容
self.state.as_ref().unwrap().content(&self)
}
pub fn request_review(&mut self) {
// take 获取值并将 self.state 的值设置为 None 便于重置值
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
// take 获取值并将 self.state 的值设置为 None 便于重置值
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
} rust// main.rs
use demo::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today!");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
// 未发布没有内容
post.approve();
assert_eq!("I ate a salad for lunch today!", post.content());
println!("完成!");
}状态模式的取舍权衡
- 缺点
- 状态之间的代码是相互耦合的
- 需要重复实现一些逻辑代码
将状态和行为编码为类型
- 将状态编码为不同的类型
- Rust 类型检查系统会通过编译时错误来阻止用户使用无效的状态
rust// lib.rs
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(&mut self) -> PendingReviewPost {
PendingReviewPost {
content: self.content.to_string(),
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
} rust// main.rs
use demo::{DraftPost, PendingReviewPost, Post};
fn main() {
let mut post: DraftPost = Post::new();
post.add_text("I ate a salad for lunch today!");
let post: PendingReviewPost = post.request_review();
let post: Post = post.approve();
assert_eq!("I ate a salad for lunch today!", post.content());
println!("完成!");
}总结
- Rust 不仅能实现面向对象的设计模式,还可以支持更多的模式
- 例如状态和行为编码为状态
- 面向对象的经典模式并不总是 Rust 编程实践中的最佳选择,因为 Rust 具有所有权等其他面向对象语言没有实现的特性
二十九、模式匹配
Rust 中的一种特殊语法,用于匹配负责和简单数据结构
将模式与匹配表达式和其他构造结合使用,可以更好的控制程序的控制流
模式由以下元素(的一些组合)组成
- 字面量
- 解构的数组、
enum、struct和tuple - 变量
- 通配符
- 占位符
想要使用模式,需要将其与某个值进行比较
- 如果模式匹配,就可以在代码中使用这个值的相应部分
用到模式的地方
match 的 Arm(分支)
match表达式的要求- 详尽(包含所有可能性)
- 特色的模式
_(下划线)- 他会匹配任何东西
- 不会绑定到变量
- 通常用于
match的最后一个分支,或用于忽略某些值
rustmatch Value {
pattern => expression,
pattern => expression,
pattern => expression,
}条件 if let 表达式
if let表达式主要是作为一种简短的方式来等价的代替只有一个匹配项的match
if let可选的可以拥有else,包括:
else ifelse if let但
if let不会加内存穷尽性
rustfn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {}, not today", color);
} else if is_tuesday {
println!("Today is Green");
} else if let Ok(age) = age {
if age > 30 {
println!("Using default color");
} else {
println!("Using default color");
}
} else {
println!("Using default color");
}
}while let 条件循环
只要模式满足匹配条件,那它允许
while循环一直运行
rustfn main() {
let mut stack = Vec::new();
stack.push(1);
stack.push(2);
stack.push(3);
while let Some(top) = stack.pop() {
println!("{}", top)
}
}for 循环
for循环中模式就是紧随for关键字后的值
rustfn main() {
let v = vec![1, 2, 3,4, 5];
for (index, value) in v.iter().enumerate() {
println!("{} {}", index, value);
}
}let 语句
let语句也是模式
let pattern = expression
rustfn main() {
let v = (1, 2, 3, 4, 5);
let (a, b, c, d, e) = v;
}函数参数
函数参数也可以是模式
rustfn foo(x: i32) {
println!("Hello, world!");
}
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("The point is at {}, {}", x, y);
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}可辩驳性:模式是否会无法匹配
- 模式有两种形式:可辩驳的、无可辩驳的
- 能匹配任何可能传递的值的模式:无可辩驳的
- 例如
let x = 5;
- 例如
- 对某些可能的值,无法进行匹配的模式:可辩驳的
- 例如:
if ley Some(x) = a_value;
- 例如:
模式语法
匹配字面值
模式可以直接匹配字面值
rustfn main() {
let x = 1;
match x {
1 => println!("x is1"),
2 => println!("x is 2"),
_ => println!("x is something else"),
}
}匹配命名变量
命名的变量是可匹配任何值的无可辩驳模式
rustfn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got a Some(50)"),
Some(y) => println!("Matched, y = {:?}", y),
_ => println!("Got something"),
}
println!("at the end: x = {:?}, y = {:?}", x, y)
}多重模式
在
match表达式中,使用|语法(就是或的意思),可以匹配多种模式
rustfn main() {
let x = 1;
match x {
1 | 2 => println!("x is 1 or 2"),
3 => println!("x is 3"),
_ => println!("x is something else"),
}
}使用 ..= 来匹配某个范围的值
rustfn main() {
let x = 1;
match x {
1..=5 => println!("x is 1 in 5"),
_ => println!("x is something else"),
}
let x = 'c';
match x {
'a'..='z' => println!("x is a letter"),
_ => println!("x is something else"),
}
}解构以分解值
可以使用模式来解构
struct、enum、tuple,从而引用这些类型值的不同部分
解构 struct
ruststruct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 1, y: 2 };
let Point { x: a, y: b } = p;
println!("{} | {}", a, b);
let Point { x, y } = p;
println!("{} | {}", x, y);
match p {
Point { x, y: 0 } => {
println!("{} | {}", x, y);
}
Point { x: 0, y } => {
println!("{} | {}", x, y);
}
Point { x, y } => println!("On neither axis: ({}, {})", x, y),
}
}解构 enum
rustenum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 255, 255, 0);
match msg {
Message::Quit => {
println!("quit");
}
Message::Move { x, y } => {
println!("move to x: {}, y: {}", x, y);
}
Message::Write(text) => {
println!("write {}", text);
}
Message::ChangeColor(r, g, b, a) => {
println!("change color to r: {}, g: {}, b: {}, a: {}", r, g, b, a);
}
}
}解构嵌套的 struct 和 enum
rustenum Color {
Rgba(u8, u8, u8, u8),
Hsv(u8, u8, u8),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 255, 255));
match msg {
Message::Quit => {
println!("quit");
}
Message::Move { x, y } => {
println!("move to x: {}, y: {}", x, y);
}
Message::Write(text) => {
println!("write {}", text);
}
Message::ChangeColor(Color::Hsv(r, g, b)) => {
println!("change color to r: {}, g: {}, b: {}", r, g, b);
}
_ => (),
}
}解构 struct 和 tuple
ruststruct Point {
x: i32,
y: i32,
}
fn main() {
let ((a, b), Point { x, y }) = ((3, 10), Point { x: 2, y: 9 });
println!("{} | {} | {} | {}", a, b, x, y);
}在模式中忽略值
使用 _ 来忽略整个值
rustfn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {}", y);
}
fn main() {
foo(3, 4)
}使用嵌套的 _ 来忽略值的一部分
rustfn main() {
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite and existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {:?}", setting_value);
let numbers = (2, 4, 8, 16, 32, 64);
match numbers {
(first, _, third, _, fifth, _) => {
println!("Some numbers: {}, {}, {}", first, third, fifth)
}
}
}通过使用 _ 开头命名来忽略未使用的变量
rustfn main() {
let _x = 5;
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string")
}
// println!("{:?}", s) // [!code warning] 没有所有权 当_s为_ 时就可用
}使用 .. 来忽略值的剩余部分
ruststruct Point {
x: i32,
y: i32,
z: i32,
}
fn main() {
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => {
println!("x is {}", x);
}
}
let numbers = (1, 2, 3, 4, 5);
match numbers {
(one, .., five) => {
println!("one is {} and five is {}", one, five);
}
}
}使用 match 守卫来提供额外的条件
match守卫就是match arm模式后额外的if条件,想要匹配该条件也必须满足
match守卫适用于比单独的模式更复杂的场景
rustfn main() {
let num = Some(4);
let y = 5;
match num {
Some(x) if x < 5 => println!("less than five: {}", x),
Some(x) if x == y => println!("x=y > {}", x),
Some(5) | Some(6) if y > 0 => println!("x=5"),
Some(x) => println!("{}", x),
None => println!("none"),
}
}@ 绑定
@符号让我们可以创建一个变量,该变量可以在测试某个值是否与模式匹配的同时保存该值
rustenum Message {
Hello { id: i32 },
}
fn main() {
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello {
id: id_variable @ 3..=7,
} => println!("{}", id_variable),
Message::Hello { id: 10..=12 } => println!("two"),
Message::Hello { id } => println!("other {id}"),
}
}三十、高级特性
不安全 Rust
匹配命名变量
- Rust 中隐藏着第二个语言,他没有强制内存安全保证:
Unsafe Rust(不安全的 Rust)- 和普通的 Rust 一样,但提供了额外的 “超能力”
Unsafe Rust存在的原因- 静态分析是保守的
- 使用
Unsafe Rust:我知道直接在做什么,并承担想用风险
- 使用
- 计算机硬件本身就是不安全的,Rust 需要能够进行底层系统编程
- 静态分析是保守的
Unsafe 超能力
- 使用
unsafe关键字来切换到unsafe Rust,开启一个快,里面放着unsafe代码 - Unsafe Rust 里可以执行的四个动作(
unsafe超能力)- 解引用原始指针
- 调用
unsafe函数或方法 - 访问或修改可变的静态变量
- 实现
unsafe trait
- 注意:
unsafe并没有关闭借用检查或停用其它安全检查- 任何内存安全相关的错误必须留在
unsafe块里 - 尽可能隔离
unsafe代码,最好将其封装在安全的抽象里,提供安全的API
解引用原始指针
- 原始指针
- 可变的:
*mut T - 不可变的:
*const T意味着指针在解引用后不能直接对其进行赋值 - 注意:这里的
*部署解引用符号,他是类型名的一部分
- 可变的:
- 与应用不同,原始指针:
- 允许通过同时具有具有不可变和可变指针或多个指向同一位置的可变指针来忽略借用规则
- 无法保证能指向合理的内存
- 允许为
null - 不实现任何自动清理
- 放弃保证的安全,换取更好的性能和与其他语言或硬件接口的能力
rust
fn main() {
let mut num = 5;
let r1 = &num as *const i32;
let r2 = &mut num as *mut i32;
unsafe {
// [!code warning] 解引用原始指针只能在 unsafe 代码块中
println!("{:p}", r1);
println!("{}", *r1);
println!("{:p}", r2);
println!("{}", *r2);
}
let address = 0x012345usize;
let ptr = address as *const i32;
unsafe {
// [!code warning] 非法访问
println!("{:p}", ptr);
println!("{}", *ptr)
}
}- 为什么要用原始指针?
- 与C语言进行接口交互
- 构建借用检查器无法理解的安全抽象
调用 unsafe 函数或方法
unsafe函数或方法:在定义前加上了unsafe关键字- 调用前需要手动满足一些条件(主要依靠文档中的要求),因为 Rust 无法对这些条件进行验证
- 需要在 unsafe 块里进行调用
rustunsafe fn dangerous() {
println!("This is dangerous!");
}
fn main() {
unsafe {
dangerous();
}
// dangerous(); // [!code warning] unsafe 块外调用是不安全的无法调用
}创建 unsafe 代码的安全抽象
- 函数包含
unsafe代码并不意味这需要将真个函数标记为unsafe - 将
unsafe代码包裹在安全函数中是一个常见的抽象
rustuse std::slice;
fn split_at_mut(slice: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = slice.len();
assert!(mid <= len);
// (&mut slice[..mid], &mut slice[mid..len]) // [!code warning] 认为不安全无法这样使用
let ptr = slice.as_mut_ptr();
unsafe {
(
// [!code warning] 从 ptr(原始指针) 往后取 mid(长度) 个切片
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), slice.len() - mid),
)
}
}
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let (left, right) = v.split_at_mut(3);
assert_eq!(left, &mut [1, 2, 3]);
assert_eq!(right, &mut [4, 5, 6]);
}使用 extern 函数调用外部代码
extern关键字:简化创建和使用外部函数接口(FFI)的过程- 外部函数接口(
FFI全名Foreign Function Interface):它允许一种编程语言定义函数,并让其它编程语言能调用这些函数 extern块中声明的任何都是不安全的
rustextern "C" { // [!code warning] 调用语言的名称
fn abs(input: i32) -> i32; // [!code warning] 调用函数的名称和签名
}
fn main() {
unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)) }
}- 应用二进制接口(
ABI,Application Binary Interface):定义函数在汇编层的调用方式 - “
C” ABI 是最常见的 ABI,它遵循 C 语言的 ABI
从其他语言来调用 Rust 函数
- 可以使用
extern创建接口,其他语言通过他们可以调用 Rust的函数 - 在
fn前添加extern关键字,并指定 ABI - 还需要添加
#[no_mangle]注解:避免 Rust 在编译时改变它的名称
rust#[no_mangle]
pub extern "C" fn call_form_c() {
println!("Just called a Rust function from C!");
}
fn main() {}访问或修改一个可变静态变量
- Rust支持全局变量,但因为所有权机制可能产生某些问题,例如数据竞争
- 在 Rust 里,全局变量叫做静态(static)变量
rust
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("name is: {HELLO_WORLD}")
}静态变量
- 静态变量与常量类似
- 命名:
SCREAMING_SNAKE_CASE - 必须标注类型
- 金泰变量只能存储 ``static` 生命周期的应用,无需显式标注
常量和不可变静态变量的区别
- 静态变量:有固定的内存地址,使用它的值总会访问同样的数据
- 常量:允许使用他们的使用对数据进行复制
- 静态常量:可以是可变的,访问呢和修改静态可变变量是不安全(
unsafe)的
ruststatic mut CONTER: u32 = 0; // 可变静态变量
fn add_to_counter(inc: u32) {
unsafe {
CONTER += inc;
}
}
fn main() {
add_to_counter(3);
unsafe {
println!("{}", CONTER);
}
}
实现不安全的(unsafe)trsit
- 当某个
trait中存在至少一个方法拥有编译器无法校验的不安全因素时,就称这个trait是不安全的 - 声明
unsafe trait:在顶以前加unsafe关键字- 该
trait只能在unsafe代码块中实现
- 该
rustunsafe trait Foo {
fn foo(&self);
}
unsafe impl Foo for i32 {
fn foo(&self) {
println!("i32");
}
}何时使用 unsafe 代码
- 编译器无法保证内存安全,保证
unsafe代码正确并不简单 - 有充足理由使用
unsafe代码时,就可以这样做 - 通过显式标记
unsafe,可以在出现问题时轻松定位
高级 Trait
在 Trait 的定义中使用关联类型来指定占位类型
- 关联类型
associated type是Trait中的类型占位符,它可以用于Trait的方法签名中- 可以定义包含某些类型的
Trait,而在实现前无需知道这些类型是什么
- 可以定义包含某些类型的
rustpub trait Iterator {
type Item; // 类型占位符
fn next(&mut self) -> Option<Self::Item>;
}
fn main() {
println!("Hello, world!")
}关联类型和泛型的区别
| 泛型 | 关联类型 |
|---|---|
| 每次实现 Trait 时标注类型 | 无需标注类型 |
| 可以为一个类型多次实现某个 Trait(不同的泛型参数) | 无法为单个类型多次实现某个 Trait |
默认泛型参数和运算符重载
- 可以在使用泛型参数时为泛型指定一个默认的具体类型
- 语法:
<PlaceholderType=ConcreteType> - 这种使用方式常用于运算符重载 (
operator overloading) - Rust 不允许创建自己的运算符及重载任意的运算符
- 但可以通过实现
std::ops中列出的那些 trait 来重载一部分相应的运算符
rustuse std::ops::Add;
#[derive(Debug, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Point { x: 1, y: 2 } + Point { x: 3, y: 4 },
Point { x: 4, y: 6 }
);
} rustuse std::ops::Add;
#[derive(Debug, PartialEq)]
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}
fn main() {
assert_eq!(
Millimeters(2000),
Millimeters(1000) + Meters(1)
);
}默认泛型参数的主要应用场景
- 扩展一个类型而不破坏现有代码
- 允许在大部分用户都不需要的特定场景下进行自定义
完全限定语法 (Fully Qualified Syntax)如何调用同名方法
完全限定语法:<Type as Trait>::function(receiver_if_method, netx_arg, ...);
- 可以在任何调用函数或方法的地方使用
- 允许忽略那些从其他上下文能推到出来的部分
同名函数调用示例
rusttrait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Waving magic wand...");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
Pilot::fly(&person);
Wizard::fly(&person);
}
同名函数调用反例
rusttrait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
// println!("A baby dog is called a {}", Animal::baby_name()); [!code error] 没有参数无法推断实现
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}使用 supertrait 来要求 trait 附带其他 trait 的功能
- 需要在一个
trait中使用其他trait的功能- 需要被依赖的
trait也被实现 - 那个被依赖的
trait就是当前trait的supertrait
- 需要被依赖的
rustuse std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
// 依赖 fmt::Display trait 的 to_string() 方法
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {} *", output);
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}使用 newtype 模式在外部类型上实现外部 trait
- 孤儿规则:只有当
trait或类型定义在本地包时,才能为该类型实现这个trait - 可以通过
newtype来绕过这一规则- 利用
tuple struct(元组结构体)创建一个新的类型
- 利用
rustuse std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
// 通过为 Wrapper 实现 fmt::Display 特征,实则为 Vec<String> 实现了 fmt::Display 特征
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {}", w);
}高级类型
使用 newtype 模式实现类型安全和抽象
newtype模式功能- 用来静态保证各种值之间不会混淆并表明值的单位
- 为类型的某些细节提供抽象能力
- 通过轻量级的分装来隐藏内部实现细节
使用类型别名创建类型同义词
- Rust 提供了类型别名的功能
- 为现有类型生产另外的名称(同义词)
- 并不是一个独立的类型
- 使用
type关键字
- 主要用途:减少代码字符重复
rusttype Kilometers<T> = T;
fn main() {
let x: i32 = 5;
let y: Kilometers<i32> = 10;
println!("x + y = {}", x + y);
}Never 类型
- 有一个名为
!的特殊类型- 他没有任何值,一边称为空类型(
empty type) - 倾向于叫它
never类型,因为它在不返回的函数中充当返回类型
- 他没有任何值,一边称为空类型(
- 不返回值的函数也被称做发散函数(
diverging function)
rustfn bar() -> ! {
// error: `!` 无法创建返回,因为loop死循环不会返回
loop {
println!("Hello, world!")
}
}
fn main() {
let guess = "42";
loop {
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue, // [!code error] 此时返回的也是 never 类型,但 never 类型能被转为任意类型
};
}
}
动态大小和 Sized Trait
- Rust 需要在编译时确定为一个特定类型的值分配多少空间
- 动态大小的类型(
Dynamically Sized Types,DST)的概念:- 编写代码时使用只有在允许时才能确定大小的值
str是动态大小的类型(不是&str):只有运行时才能确定字符串的长度- 下列代码无法正常工作
let s1: str = "Hello there!"let s2: str = "How's it going؋"
- 使用
&str来解决str的地址str的长度
- 下列代码无法正常工作
Rust 使用动态大小类型的通用方式
- 附带一些额外的元数据来存储动态信息的大小
- 使用动态大小类型是总会把他的值放在某种指针后面
另一种动态大小类型 trait
- 每个
trait都是一个动态大小的类型,可以通过名称对其进行引用 - 为了将
trait用作trait对象,必须将他防止在某种指针之后- 例如
&dyn Trait或Box<dyn Trait>、Rc<dyn Trait之后
- 例如
Sized trait
- 为了处理动态大小类型,Rust 提供了一个
Sized trait来确定一个类型的大小在编译时是否已知 - 编译时可以计算出大小的类型会自动实现这个
trait - Rust 还会为每一个泛型函数隐式的添加
Sized约束
rustfn generic<T>(t: T) {}
// 上方函数会被隐式转为下方函数
fn generic<T: Sized>(t: T){}- 默认情况下,泛型函数只能被用于编译时已经知道大小的类型,可以通过特殊语法接触这一限制
?Sized trait 约束
rustfn generic<T: Sized>(t: T){}
// 此时 T 的大小可能是未知的,所以变成了 T 的引用
fn generic<T: ?Sized>(t: &T){}T可能是也可能不是Sized- 这个语法只能用在
Sized扇面,不能用于其他trait
高级函数和闭包
函数指针
- 可以将函数传递给其他函数
- 函数在传递中会被强制转换成
fn类型 fn类型就是 “函数指针(function pointer)”
rustfn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) {
println!("{}", f(arg));
}
fn main() {
let answer = do_twice(add_one, 5);
}函数指针与闭包的不同
fn是一个类型,不是一个trait- 可以直接指定
fn为参数类型,不用声明一个以Fn trait为约束的泛型参数
- 可以直接指定
- 函数指针实现了全部 3 种闭包
trait(Fn,FnMut,FnOnce)- 总是可以把函数指针用作参数传递给一个接收闭包的函数
- 所以倾向于搭配闭包
trait的泛型来编写函数:可以同时接收闭包和普通函数
- 某些情况下,只想接收
fn而不接收闭包- 与外部不支持闭包的代码交互:C函数
rustfn main() {
let list_of_numbers = vec![1, 2, 3, 4, 5];
let list_of_strings: Vec<String> = list_of_numbers
.iter()
.map(|i| i.to_string())
.collect();
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> = list_of_numbers
.iter()
.map(ToString::to_string)
.collect();
}
fn main2() {
enum Status {
Value(u32),
Stop,
}
// 构造器也被实现了函数的调用方式所以可以传递使用
let list_of_statuses: Vec<Status> = (0u32..20)
.map(Status::Value)
.collect();
}返回闭包
- 闭包使用
trait进行表达,无法在函数中直接返回一个闭包,可以将一个实现了该trait的具体类型作为返回值
rust// fn returns_closure() -> Fn(i32) -> i31 {} [!code error] trait不可以这样用
// 没办法判断闭包的内存大小所以需要使用 Box dyn 对象包裹变为指针
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}宏
宏 macro
宏在 Rust 里指的是一组相关特性的集合称谓:
- 使用
macro_rules!构建的声明宏(declarative macro) - 三种过程宏
- 自定义
#[derive]宏,用于struct和enum,可以为其指定跟随derive属性添加的代码 - 类似属性的宏,在任何条目上添加自定义属性
- 类似函数的宏,看起来像函数调用,对其指定为参数的
token进行操作
- 自定义
函数和宏的区别
- 本质上,宏是用来编写可以生成其他代码的代码(元编程,
metaprogramming) - 函数在定义签名时,必须声明参数的个数和类型,宏可处理可变的参数
- 编译器会在解释代码前展开宏
- 宏的定义比函数复杂得多,难以阅读、理解、维护
- 在某个文件调用宏时,必须提前定义宏或将宏引入当前作用域
- 函数可以在任何位置定义和使用
macro_rules! 声明宏(弃用)
Rust最初将的宏形式:声明宏
- 类似
match的模式匹配 - 需要使用
marco_rules!
rust#[macro_export]
macro_rules! vec {
// `$x:expr` 将任何表达式捕获为 `$x`,`*` 表示零个或多个
( $( $x:expr ), *) => {
{
let mut temp_vec = Vec::new();
// `$x` 捕获表达式,`*` 表示零个或多个,把他们放到 `temp_vec` 中
$(
temp_vec.push($x);
)*
temp_vec
}
};
}基于属性来生成代码的过程宏
这种形式更像函数(某种形式的过程)一些
- 接收并操作输入的 Rust 代码
- 生成另外一些 Rust 代码作为结果
三种过程宏:
- 自定义派生
- 属性宏
- 函数宏
创建过程宏时:
- 宏定义必须单独放在它们自己的包中,并使用特殊的包类型
rustuse proc_macro;
use proc_macro::TokenStream;
#[proc_macro]
pub fn some_name(input: TokenStream) -> TokenStream {
input
}注意: 使用 Cargo 时,定义过程宏的 crate 的配置文件里要使用
proc-macro键做如下设置:
toml[lib]
proc-macro = true自定义 derive 宏
需求:
- 创建一个
hello_macro包,定义一个拥有关联函数hello_macro的HelloMacro trait - 我们提供一个能自动实现
trait的过程宏 - 在它们的类型上标注
#[derive(HelloMacro)],进而得到hello_macro的默认实现
文件结构树:
plaintextworkspase ├─ Cargo.lock ├─ Cargo.toml ├─ pancakes │ ├─ Cargo.toml │ └─ src │ └─ main.rs ├─ hello_macro_derive │ ├─ Cargo.toml │ └─ src │ └─ lib.rs └─ hello_macro ├─ Cargo.toml └─ src └─ lib.rs
touch Cargo.toml
toml# Cargo.toml
[workspace]
resolver = "2"
members = [
"hello_macro",
"hello_macro_derive",
"pancakes",
]cargo new hello_macro --lib
rust// hello_macro/src/lib.rs
pub trait HelloMacro {
fn hello_macro();
}cargo new hello_macro_derive --lib
toml# hello_macro_derive/Cargo.toml
[package]
name = "hello_macro_derive"
version = "0.1.0"
edition = "2021"
[lib]
proc-macro = true
[dependencies]
syn = "0.14.4"
quote = "0.6.3"
rust// hello_macro_derive/src/lib.rs
extern crate proc_macro;
use crate::proc_macro::TokenStream;
use quote::quote; // 可以把 syn 转换的数据结构重新转换为rust代码
use syn; // 用于把rust代码转为我们可以操作的结构
// #[derive(HelloMacro)] hello_macro_derive 会被自动调用
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
let ast = syn::parse(input).unwrap();
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let gen = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My namr is {}", stringify!(#name)) // 接收一个表达式但是不计算,把他转为字符串
}
}
};
// 转为 TokenStream
gen.into()
}cargo new pancakes
toml# pancakes/Cargo.toml
[package]
name = "pancakes"
version = "0.1.0"
edition = "2021"
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro_derive" } rust// pancakes/src/lib.rs
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}类似属性的宏
属性宏与自定义 derive 宏类似
- 允许创建新的属性
- 但不是为
derive属性生成代码
属性宏更加灵活
derive只能用于struct和enum- 属性宏可以用于任意条目,例如函数
rust#[route(GET, "/")]
fn index() {}
// 定义方式
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {}类似函数的宏
- 函数宏定义类似于函数调用的宏,但比普通函数更加灵活
- 函数宏可以接收
TokenStream作为参数 - 与另外两种过程宏一样,在定义中使用 Rust 代码来操作
TokenStream
rust// 解析sql语句的宏
let sql = sql!(SELECT * FROM posts WHERE id=1 );
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {}三十一、构建Web服务器
构建多线程 Web服务器
- 在
socket上监听TCP连接 - 解析少量的
HTTP请求 - 创建一个合适的
HTTP响应 - 使用线程池改进服务器的吞吐量
此处并不是最佳实现
文件结构如下:
plaintextwebserver ├─ 404.html ├─ Cargo.lock ├─ Cargo.toml ├─ hello.html └─ src ├─ lib.rs └─ main.rs
404.html
html<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>404</title>
</head>
<body>
<h1>你的页面走丢了</h1>
</body>
</html>hello.html
html<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>Hello World!</h1>
<p>This is a test.</p>
</body>
</html>lib.rs
rust// src\lib.rs
use std::sync::{mpsc, Arc, Mutex}; // mpsc 用于创建消息传递通道, Arc 和 Mutex 用于创建线程安全的数据结构
use std::thread;
enum Message {
/// Message enum
///
/// 用于向线程池中传递任务和结束信号
NewJob(Job),
Terminate,
}
pub struct ThreadPool {
/// ThreadPool struct
///
/// 线程池对象,维护了一个 `workers` 工作线程池,以及一个 `sender` 用于向线程池中传递任务和结束信号
workers: Vec<Worker>,
sender: mpsc::Sender<Message>,
}
// struct Job;
impl ThreadPool {
/// 创建线程池.
///
/// size 是池中的线程数
///
/// # Panics
///
/// 如果大小为零,'new' 函数将 panic。
pub fn new(size: usize) -> ThreadPool {
// 确保线程池大小不为零
assert!(size > 0);
// 创建一个消息传递通道,用于传递任务和结束信号
let (sender, receiver) = mpsc::channel();
// 创建一个 Arc 和 Mutex,用于包装接收端,使接收端能在多个线程间共享所有权
let receiver = Arc::new(Mutex::new(receiver));
// 创建一个预分配 size Vec 空间
let mut workers = Vec::with_capacity(size);
// 创建 size 个工作线程,并放入 Vec 中
for id in 0..size {
// 使用 Arc::clone 来创建一个共享所有权的接收端
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
// 返回线程池对象
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
// F: FnOnce() + Send + 'static 来自 thread::spawn 函数的参数类型
where
F: FnOnce() + Send + 'static,
{
// 创建一个 Box 来包装任务闭包函数
let job = Box::new(f);
// 将任务闭包函数发送到消息传递通道中
self.sender.send(Message::NewJob(job)).unwrap();
}
}
impl Drop for ThreadPool {
/// 线程池析构函数,用于向线程池中发送结束信号,并等待所有工作线程结束
fn drop(&mut self) {
println!("Sending terminate message to all workers.");
// 向消息传递通道中发送线程数等量的结束信号
for _ in &mut self.workers {
self.sender.send(Message::Terminate).unwrap();
}
println!("Shutdown down all workers.");
// 循环等待所有工作线程结束
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
/// Worker struct
///
/// 工作线程对象,维护了一个线程句柄和线程 ID
id: usize,
// thread::JoinHandle 类型来自 thread::spawn 函数的返回值
thread: Option<thread::JoinHandle<()>>,
}
trait FnBox {
/// FnBox trait
///
/// 用于定义一个函数指针,用于在 trait 中实现函数指针的调用
///
/// # Examples
///
/// ```
/// fn foo() {
/// println!("foo");
/// }
///
/// fn bar() {
/// println!("bar");
/// }
///
/// fn main() {
/// let f = foo;
/// let b = bar;
/// let fb = f as Box<FnBox>;
/// fb();
/// let fb = b as Box<FnBox>;
/// fb();
/// }
/// ```
fn call_box(self: Box<Self>);
}
impl<F: FnOnce()> FnBox for F {
/// FnBox trait 的实现
///
/// 掉用 `FnOnce` 函数指针, F类型为实现了 `FnOnce` 的所有 `FnBox` 的函数
fn call_box(self: Box<F>) {
(*self)()
}
}
type Job = Box<dyn FnBox + Send + 'static>; // Job 类型来自 thread::spawn 函数的参数类型,使用 `Box` 包裹为了编译阶段能获取大小
impl Worker {
/// 创建一个工作线程,并把线程句柄放入 Vec 中
///
/// # Arguments
///
/// * `id` - 工作线程 ID
/// * `receiver` - 用于接收消息的接收端
///
/// # Returns
///
/// * `Worker` - 工作线程对象
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Message>>>) -> Worker {
// 创建一个线程,并把线程句柄放入 Vec 中
let thread = thread::spawn(move || loop {
let message = receiver.lock().unwrap().recv().unwrap();
match message {
Message::NewJob(job) => {
println!("Worker {} got a job; executing.", id);
job.call_box();
}
Message::Terminate => {
println!("Worker {} was told to terminate.", id);
break;
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}main.rs
rustuse std::{fs, thread};
use std::io::{Read, Write};
use std::net::{TcpListener, TcpStream};
use std::time::Duration;
use webserver::ThreadPool;
fn main() {
println!("Server is running at 127.0.0.1:8001");
let listener = TcpListener::bind("127.0.0.1:8001").unwrap();
let pool = ThreadPool::new(4);
// take(2) 只能迭代 2 个连接
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
// tcp 请求的内部状态可能会改变所以需要使用 mut
fn handle_connection(mut stream: TcpStream) {
// 创建了一个存放数据的缓存 512 字节
let mut buffer = [0; 512];
// 从 stream 中读取数据到 buffer 中
stream.read(&mut buffer).unwrap();
// 输出 buffer 中的内容
// println!("-----------------------------------");
// println!("Request: {}", String::from_utf8_lossy(&buffer[..]));
// 请求
// Method Request-URI HTTP-Version CRLF
// Header CRLF
// message-body
// 响应
// HTTP-Version Status-Code Reason-Phrase CRLF
// Header CRLF
// message-body
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK\r\nContent-Type: text/html", "hello.html")
} else if buffer.starts_with(sleep) {
thread::sleep(Duration::from_secs(3));
("HTTP/1.1 200 OK\r\nContent-Type: text/html", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND\r\nContent-Type: text/html", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!("{}\r\nContent-Length: {}\r\n\r\n{}", status_line, contents.len(), contents);
stream.write(response.as_bytes()).unwrap();
stream.flush().unwrap();
println!("-");
}